
大查询SQL:用移动引用在滑动时间窗口上标记日期
这个职位是干什么用的?
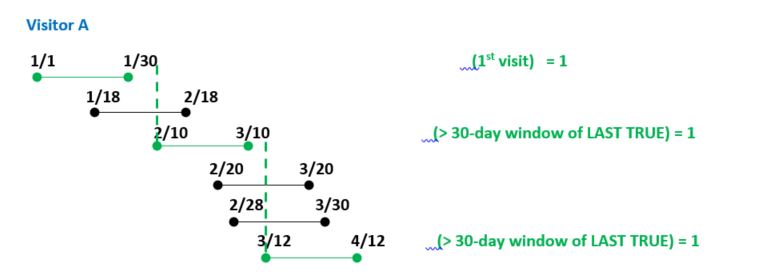
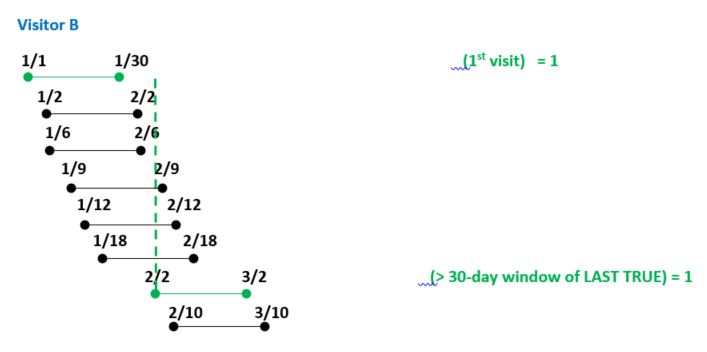
作为一个团队,我们希望根据以下情况将每个日期标记为真或假;
1) visit_date是第一次访问访问者的,然后是TRUE
2)在第一次访问之后的所有访问日期。
( a)与最后一个真实的visit_date (特此最后一个真)相比,如果visit_date位于最后一个真的30天前瞻性窗口内,则为FALSE;
我用的是什么数据?
网站数据与访问者和visit_date。
为访问者创建的每一个新会话记录visit_date。我们对数据进行操作,使每个访问者每一个日期只获得一条记录。
发行:
简单的滞后函数和引导函数没有帮助,因为;
1)给出一个新的真标记后,上真的参考位置不断变化。
( a)我们必须检查的记录数量,以确定上一次真正的更改的访问者数量。下一个TRUE可以是2行或15行;这取决于访问者。
实际上,我们无法在中创建一个循环,以便
- 检查visit_date是否符合标准
- 如果它将其标记为TRUE,也将最后一个真引用更改为该visit_date
- 重复这个过程,直到最后一次记录给访客。
使用的查询:
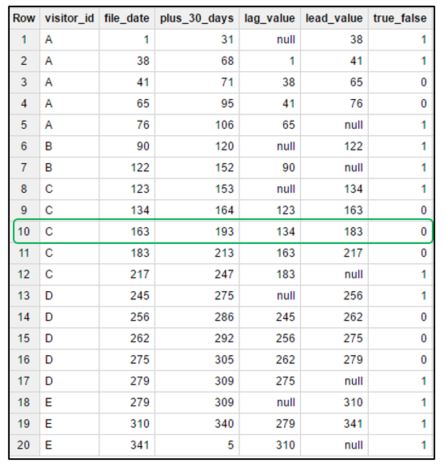
第一个表(table_id)就是为了得到以下的计算
访问者唯一标识符
visit_date访问日
plus_30_days 30天+访问日
以上一行的lag_value值visit_date
下一行的lead_value值visit_date
为了便于使用,所有值都转换为DAYOFYEAR ()
基于上表,我使用了以下查询
SELECT *
, CASE WHEN lag_value IS NULL THEN 1
WHEN visit_date - lag_value > 30 THEN 1
WHEN lead_value IS NULL THEN 1
ELSE 0 END AS true_false
FROM [project_id:dataset.table_id]
ORDER BY visitor, visit_date产出:
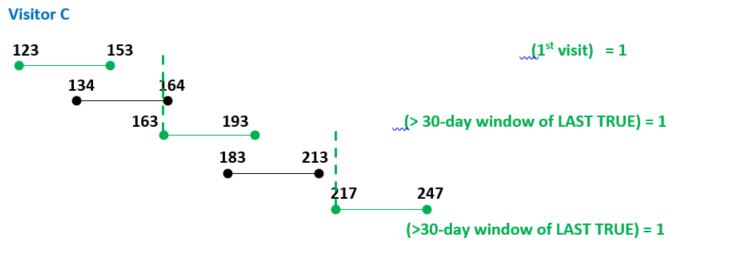
绿色框应该是真
因为
采取的行动:
( 1)我尝试了引导和滞后函数。
2)检查了web,可以转换为BIGQUERY >>的普通SQL函数找不到循环函数。
3)问我的团队领导>>同样的问题
4)实验>>相同输出的时间长达3小时
表以供参考(未格式化)
visitor_id file_date plus_30_days lag_value lead_value true_false
A 1 31 null 38 1
A 38 68 1 41 1
A 41 71 38 65 0
A 65 95 41 76 0
A 76 106 65 null 1
B 90 120 null 122 1
B 122 152 90 null 1
C 123 153 null 134 1
C 134 164 123 163 0
C 163 193 134 183 0
C 183 213 163 217 0
C 217 247 183 null 1
D 245 275 null 256 1
D 256 286 245 262 0
D 262 292 256 275 0
D 275 305 262 279 0
D 279 309 275 null 1
E 279 309 null 310 1
E 310 340 279 341 1
E 341 5 310 null 1回答 1
Stack Overflow用户
发布于 2016-07-21 15:55:29
试试下面。
SELECT visitor_id, file_date, true_false FROM JS( // input table
( SELECT visitor_id, GROUP_CONCAT(STRING(100000 + file_date), ';') AS visits FROM
(SELECT 'A' AS visitor_id, 1 AS file_date), (SELECT 'A' AS visitor_id, 38 AS file_date), (SELECT 'A' AS visitor_id, 41 AS file_date), (SELECT 'A' AS visitor_id, 65 AS file_date),
(SELECT 'A' AS visitor_id, 76 AS file_date), (SELECT 'B' AS visitor_id, 90 AS file_date), (SELECT 'B' AS visitor_id, 122 AS file_date), (SELECT 'C' AS visitor_id, 123 AS file_date),
(SELECT 'C' AS visitor_id, 134 AS file_date), (SELECT 'C' AS visitor_id, 163 AS file_date), (SELECT 'C' AS visitor_id, 183 AS file_date), (SELECT 'C' AS visitor_id, 217 AS file_date),
(SELECT 'D' AS visitor_id, 245 AS file_date), (SELECT 'D' AS visitor_id, 256 AS file_date), (SELECT 'D' AS visitor_id, 262 AS file_date), (SELECT 'D' AS visitor_id, 275 AS file_date),
(SELECT 'D' AS visitor_id, 279 AS file_date), (SELECT 'E' AS visitor_id, 279 AS file_date), (SELECT 'E' AS visitor_id, 310 AS file_date), (SELECT 'E' AS visitor_id, 341 AS file_date)
GROUP BY visitor_id
) ,
// input columns
visitor_id, visits,
// output schema
"[{name: 'visitor_id', type: 'string'},
{name: 'file_date', type: 'integer'},
{name: 'true_false', type: 'integer'}]",
// function
"function(r, emit){
var visits = r.visits.split(';');
visits.sort();
plus_30_days = 0;
for (var i = 0; i < visits.length; i++) {
file_date = parseInt(visits[i]) - 100000;
true_false = 0;
if (file_date > plus_30_days) {
plus_30_days = file_date + 30;
true_false = 1;
}
emit({
visitor_id: r.visitor_id,
file_date: file_date,
true_false: true_false
});
}
}")希望这能给你一个好的开始
请注意:上面的示例使用了JavaScript UDF的无文档内联版本,到目前为止,它可以快速演示/共享/尝试代码,但是.无证,因此不支持
为了在生产中使用上面的示例,您最好修改它以符合BigQuery用户定义函数文档(很少有非常简单的调整)。
https://stackoverflow.com/questions/38496591
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号