
如何在Python中打印包含汉字的文本内容?
如何在Python中打印包含汉字的文本内容?
提问于 2016-07-01 04:23:52
我使用python来提取一个网页的内容。我关注的html内容里面有一些汉字,还有其他常用的字符。
然后,我试着打印html标签及其内容,打印的文本都是乱七八糟的代码。如下所示:
<h4>绔彛:443</h4>
<h4>A瀵嗙爜:</h4>
<h4>鍔犲瘑鏂瑰紡:aes-256-cfb</h4>最初的内容如下:
<h4>端口:443</h4>
<h4>A远端:</h4>
<h4>加密方式:aes-256-cfb</h4>你能帮我在控制台上打印出正确的内容吗?我用的是python 2.7。代码片段如下所示:
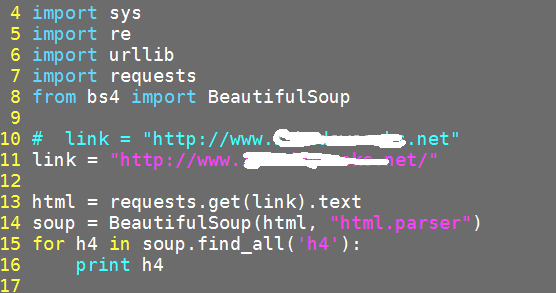
添加一个更新:
在使用lxml方法尝试了湿婆的建议之后,我得到了如下捕获结果:
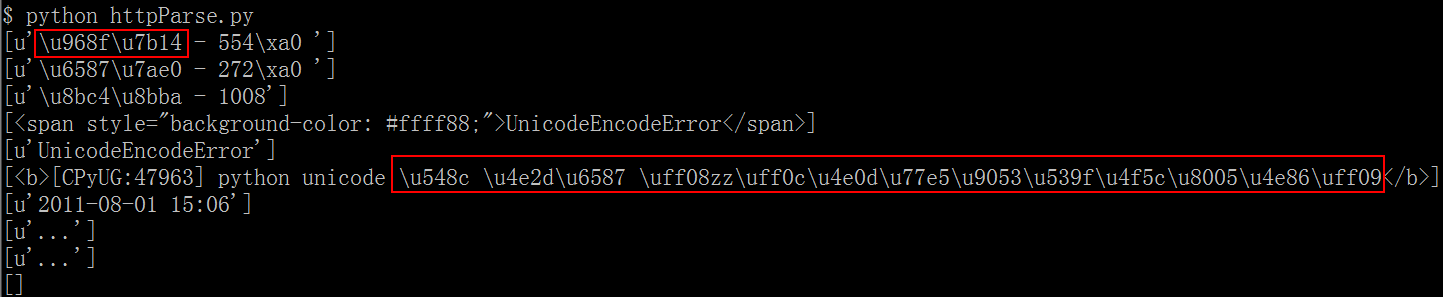
添加第二个更新:
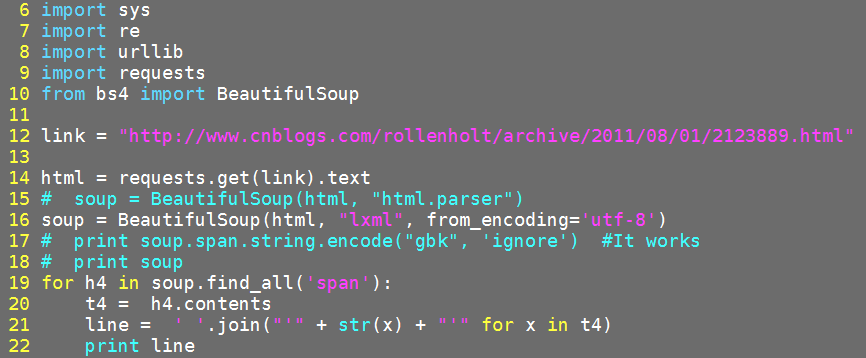
你能告诉我如何在Git bash控制台中显示原始汉字吗?
提前谢谢你!
诚挚的问候,
俊玛
回答 2
Stack Overflow用户
回答已采纳
发布于 2016-07-01 05:32:42
你可以试试:
soup=BeautifulSoup(html, "lxml", from_encoding='utf-8')
您可以通过使用firefox或chrome查看页面信息获得编码,如下所示:
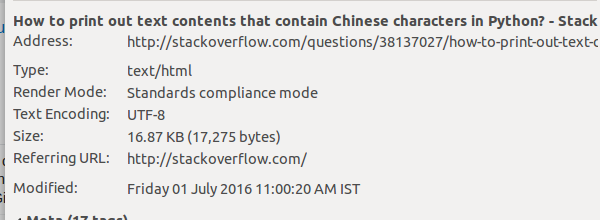
编辑:
from bs4 import BeautifulSoup
import requests
url = "http://www.cnblogs.com/rollenholt/archive/2011/08/01/2123889.html"
html=requests.get(url).text
soup=BeautifulSoup(html, "lxml", from_encoding='utf-8')
lst=soup.find_all('span')
for h in lst:
print h.string #or you could do print h我得到了下面的输出我运行它。
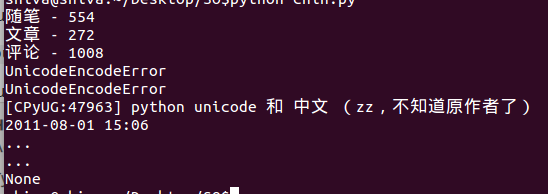
Stack Overflow用户
发布于 2016-07-01 04:28:50
>>> print u'加密方式'.encode('utf-8').decode('gbk')
鍔犲瘑鏂瑰紡您的控制台配置为处理GBK。Configure it to handle UTF-8 instead.
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/38137027
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号