
为什么释放堆内存比分配堆内存慢得多?
这是一个经验假设(分配比去分配更快)。
这也是为什么基于堆的存储(比如STL容器或其他存储)选择不将当前未使用的内存返回到系统的原因(这就是为什么出现了收缩适应的成语)。
当然,我们不应该把‘堆’内存和‘堆’数据结构混淆起来。
那么为什么取消分配比较慢,
它是特定于Windows的(我在Win 8.1上看到的)还是操作系统独立的?
是否有一些特定于C++的内存管理器自动涉及到使用'new‘/ 'delete’或整个mem。管理是否完全依赖于操作系统?(我知道C++11引入了一些垃圾收集支持,我从未真正使用过,更好地依赖旧堆栈和静态持续时间或自管理容器和RAII)。
另外,在我看到的使用旧C堆分配/去分配的愚蠢字符串的代码中,它比C++ 'new‘/ 'delete’更快吗?
请注意,P. S.的问题是而不是关于虚拟内存机制,我知道用户空间程序没有使用真正的mem。地址。
回答 5
Stack Overflow用户
发布于 2016-06-25 18:21:33
我和@Basile有同样的想法:我想知道你的基本假设是否真的(甚至接近)正确。因为您标记了问题C++,所以我用C++编写了一个快速的基准测试。
#include <vector>
#include <iostream>
#include <numeric>
#include <chrono>
#include <iomanip>
#include <locale>
int main() {
std::cout.imbue(std::locale(""));
using namespace std::chrono;
using factor = microseconds;
auto const size = 2000;
std::vector<int *> allocs(size);
auto start = high_resolution_clock::now();
for (int i = 0; i < size; i++)
allocs[i] = new int[size];
auto stop = high_resolution_clock::now();
auto alloc_time = duration_cast<factor>(stop - start).count();
start = high_resolution_clock::now();
for (int i = 0; i < size; i++)
delete[] allocs[i];
stop = high_resolution_clock::now();
auto del_time = duration_cast<factor>(stop - start).count();
std::cout << std::left << std::setw(20) << "alloc time: " << alloc_time << " uS\n";
std::cout << std::left << std::setw(20) << "del time: " << del_time << " uS\n";
}我也在Windows上使用VC++,而不是在Linux上使用gcc。但结果并没有太大的不同:释放内存比分配内存花费的时间要少得多。以下是连续三次运行的结果。
alloc time: 2,381 uS
del time: 1,429 uS
alloc time: 2,764 uS
del time: 1,592 uS
alloc time: 2,492 uS
del time: 1,442 uS但是,我要警告的是,分配和释放是由标准库处理的(主要是),因此这在一个标准库和另一个标准库之间可能是不同的(即使使用相同的编译器)。我还会注意到,如果这在多线程代码中有所改变,我也不会感到惊讶。虽然这实际上并不正确,但似乎有一些作者错误地认为,在多线程环境中释放需要锁定堆以进行独占访问。这是可以避免的,但这样做的手段不一定是立即显而易见的。
Stack Overflow用户
发布于 2016-06-25 18:18:19
关于分配内存比释放内存更快的断言对我来说有点奇怪,所以我对它进行了测试。我运行了一个测试,我在32字节块中分配了64 it的内存(对new的调用为200万次),并尝试以与分配的顺序相同的顺序删除该内存。我发现线性序去分配比分配快3%左右,随机去分配比线性分配慢10%左右。
然后,我运行了一个测试,从64 at的分配内存开始,然后再分配新内存或删除现有内存(随机)200万次。在这里,我发现去分配大约比分配慢4.3%。
因此,事实证明你是正确的--去分配比分配慢(虽然我不认为它“太慢”)。我怀疑这只是与更多的随机访问有关,但除了线性去分配速度更快之外,我没有其他证据。
来回答你的一些问题:
是否有一些C++特定的内存管理器自动涉及到使用'new‘/ 'delete'?
是。操作系统具有系统调用,这些调用将内存页(通常为4KB块)分配给进程。过程的任务是将这些页面划分为对象。尝试查找"GNU内存分配器“。
我看到使用旧的C堆分配/去分配,它比C++ 'new‘/ 'delete’更快吗?
大多数C++ new/delete实现只是在幕后调用malloc和free。然而,这并不是标准所要求的,所以在任何特定对象上始终使用相同的分配和去分配函数是个好主意。
我使用Visual 2015提供的本机测试框架在Windows 10 64位计算机上运行测试(测试也是64位的)。下面是代码:
#include "stdafx.h"
#include "CppUnitTest.h"
using namespace Microsoft::VisualStudio::CppUnitTestFramework;
namespace AllocationSpeedTest
{
class Obj32 {
uint64_t a;
uint64_t b;
uint64_t c;
uint64_t d;
};
constexpr int len = 1024 * 1024 * 2;
Obj32* ptrs[len];
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(Linear32Alloc)
{
for (int i = 0; i < len; ++i) {
ptrs[i] = new Obj32();
}
}
TEST_METHOD(Linear32AllocDealloc)
{
for (int i = 0; i < len; ++i) {
ptrs[i] = new Obj32();
}
for (int i = 0; i < len; ++i) {
delete ptrs[i];
}
}
TEST_METHOD(Random32AllocShuffle)
{
for (int i = 0; i < len; ++i) {
ptrs[i] = new Obj32();
}
srand(0);
for (int i = 0; i < len; ++i) {
int pos = (rand() % (len - i)) + i;
Obj32* temp = ptrs[i];
ptrs[i] = ptrs[pos];
ptrs[pos] = temp;
}
}
TEST_METHOD(Random32AllocShuffleDealloc)
{
for (int i = 0; i < len; ++i) {
ptrs[i] = new Obj32();
}
srand(0);
for (int i = 0; i < len; ++i) {
int pos = (rand() % (len - i)) + i;
Obj32* temp = ptrs[i];
ptrs[i] = ptrs[pos];
ptrs[pos] = temp;
}
for (int i = 0; i < len; ++i) {
delete ptrs[i];
}
}
TEST_METHOD(Mixed32Both)
{
for (int i = 0; i < len; ++i) {
ptrs[i] = new Obj32();
}
srand(0);
for (int i = 0; i < len; ++i) {
if (rand() % 2) {
ptrs[i] = new Obj32();
}
else {
delete ptrs[i];
}
}
}
TEST_METHOD(Mixed32Alloc)
{
for (int i = 0; i < len; ++i) {
ptrs[i] = new Obj32();
}
srand(0);
for (int i = 0; i < len; ++i) {
if (rand() % 2) {
ptrs[i] = new Obj32();
}
else {
//delete ptrs[i];
}
}
}
TEST_METHOD(Mixed32Dealloc)
{
for (int i = 0; i < len; ++i) {
ptrs[i] = new Obj32();
}
srand(0);
for (int i = 0; i < len; ++i) {
if (rand() % 2) {
//ptrs[i] = new Obj32();
}
else {
delete ptrs[i];
}
}
}
TEST_METHOD(Mixed32Neither)
{
for (int i = 0; i < len; ++i) {
ptrs[i] = new Obj32();
}
srand(0);
for (int i = 0; i < len; ++i) {
if (rand() % 2) {
//ptrs[i] = new Obj32();
}
else {
//delete ptrs[i];
}
}
}
};
}以下是几次测试的原始结果。所有数字都以毫秒为单位。
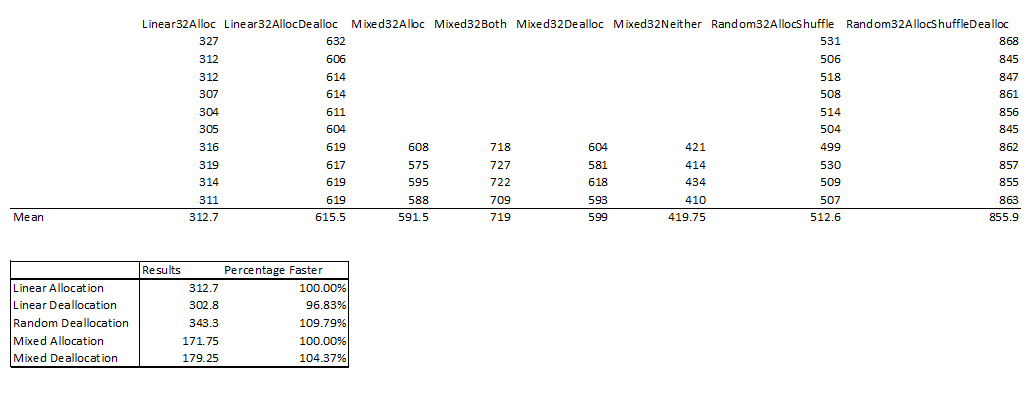
Stack Overflow用户
发布于 2016-06-25 17:59:41
我不确定你的看法。我编写了以下程序(在Linux上,希望您可以将它移植到您的系统中)。
// public domain code
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <errno.h>
#include <string.h>
#include <assert.h>
const unsigned possible_word_sizes[] = {
1, 2, 3, 4, 5,
8, 12, 16, 24,
32, 48, 64, 128,
256, 384, 2048
};
long long totalsize;
// return a calloc-ed array of nbchunks malloced zones of
// somehow random size
void **
malloc_chunks (int nbchunks)
{
const int nbsizes =
(int) (sizeof (possible_word_sizes)
/ sizeof (possible_word_sizes[0]));
void **ad = calloc (nbchunks, sizeof (void *));
if (!ad)
{
perror ("calloc chunks");
exit (EXIT_FAILURE);
};
for (int ix = 0; ix < nbchunks; ix++)
{
unsigned sizindex = random () % nbsizes;
unsigned size = possible_word_sizes[sizindex];
void *zon = malloc (size * sizeof (void *));
if (!zon)
{
fprintf (stderr,
"malloc#%d (%d words) failed (total %lld) %s\n",
ix, size, totalsize, strerror (errno));
exit (EXIT_FAILURE);
}
((int *) zon)[0] = ix;
totalsize += size;
ad[ix] = zon;
}
return ad;
}
void
free_chunks (void **chks, int nbchunks)
{
// first, free the two thirds of chunks in random order
for (int i = 0; 3 * i < 2 * nbchunks; i++)
{
int pix = random () % nbchunks;
if (chks[pix])
{
free (chks[pix]);
chks[pix] = NULL;
}
}
// then, free the rest in reverse order
for (int i = nbchunks - 1; i >= 0; i--)
if (chks[i])
{
free (chks[i]);
chks[i] = NULL;
}
}
int
main (int argc, char **argv)
{
assert (sizeof (int) <= sizeof (void *));
int nbchunks = (argc > 1) ? atoi (argv[1]) : 32768;
if (nbchunks < 128)
nbchunks = 128;
srandom (time (NULL));
printf ("nbchunks=%d\n", nbchunks);
void **chks = malloc_chunks (nbchunks);
clock_t clomall = clock ();
printf ("clomall=%ld totalsize=%lld words\n",
(long) clomall, totalsize);
free_chunks (chks, nbchunks);
clock_t clofree = clock ();
printf ("clofree=%ld\n", (long) clofree);
return 0;
} 我在Debian/Sid/x86-64 (i3770k,16 it )上用i3770k编译了它。我运行time ./mf 100000并得到:
nbchunks=100000
clomall=54162 totalsize=19115681 words
clofree=83895
./mf 100000 0.02s user 0.06s system 95% cpu 0.089 total在我的系统中,clock给CPU以微秒的时间。如果对random的调用可以忽略不计(我不知道是否如此),w.r.t。malloc & free time,我倾向于不同意您的意见。free的速度似乎是malloc的两倍。我的gcc是6.1,我的libc是Glibc 2.22。
请花时间在您的系统上编译上述基准并报告时间。
我选了Jerry's code和
g++ -O3 -march=native jerry.cc -o jerry
time ./jerry; time ./jerry; time ./jerry给出
alloc time: 1940516
del time: 602203
./jerry 0.00s user 0.01s system 68% cpu 0.016 total
alloc time: 1893057
del time: 558399
./jerry 0.00s user 0.01s system 68% cpu 0.014 total
alloc time: 1818884
del time: 527618
./jerry 0.00s user 0.01s system 70% cpu 0.014 totalhttps://stackoverflow.com/questions/38030504
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号