
长向量(长度为~1e+7到~1e+8)上的快速pnorm()计算
有没有优化pnorm的方法?我的代码中有一些瓶颈,经过大量的优化和基准测试之后,我意识到它来自对大型向量的pnorm调用。
使用microbenchmarking,我在我的机器上,如果length(u) ~ 5e+7,那么pnorm(u)需要11秒。
这里有使用Rcpp的方法吗,还是内置的pnorm已经被优化了?
任何想法都欢迎。
我在SO上找到了这些帖子:与Rcpp一起使用Rmath.h中的pnorm和如何在Rcpp上使用qnorm?。但据我所知,他们的目的是在Cpp代码中使用R函数。
回答 3
Stack Overflow用户
发布于 2016-06-25 14:14:32
在本节中,我将演示对pnorm()的快速而准确的近似。
在我们开始之前,我们需要弄清楚:我们想通过使用近似来实现什么?效率/速度/性能,对吗?但这样的效率从何而来呢?
如上所述,pnorm()计算是内存绑定的;即使我们做了近似计算,它仍然是内存边界的(因此我们不考虑进一步的并行化)。内存绑定问题
number of floating point operations : memory access = O(1)换句话说,这个比率是一些常数C。因此,我们的目标应该是减少这个常数,也就是说,我们希望减少浮点运算。
浮点运算的数目通常被报告为浮点数的加法和乘法。其他类型的浮点数操作被“转换”为此类措施。现在,让我们比较几种常见浮点操作的成本。
u <- sample(1:10/10, 5e+7, replace = TRUE)
system.time(u + u)
# user system elapsed
# 0.468 0.168 0.639
system.time(u * u)
# user system elapsed
# 0.424 0.212 0.638
system.time(u / u)
# user system elapsed
# 0.504 0.204 0.710
system.time(u ^ 1.1)
# user system elapsed
# 7.240 0.212 7.458
system.time(sqrt(u))
# user system elapsed
# 2.044 0.176 2.224
system.time(exp(u))
# user system elapsed
# 4.336 0.208 4.550
system.time(log(u))
# user system elapsed
# 2.748 0.172 2.925
system.time(round(u))
# user system elapsed
# 6.836 0.188 7.034 请注意,加法和乘法很便宜,根和对数比较昂贵,而一些运算非常昂贵,包括幂、指数和舍入。
现在让我们回到pnorm(),甚至dnorm()等等,在这里我们有一个指数项要计算。鉴于此:
system.time(pnorm(u))
# user system elapsed
# 11.016 0.160 11.193
system.time(dnorm(u))
# user system elapsed
# 8.844 0.164 9.022 我们发现,计算pnorm()和dnorm()的大部分时间都归因于指数计算。pnorm()比dnorm()花费更长的时间,因为它还有一个积分!
现在,我们的目标是相当明确的:我们希望用非常便宜的东西来替换昂贵的pnorm() 评估,理想情况下只涉及加法/乘法。我们可以吗??
历史上有许多近似方法。@Ben提到了逻辑近似。R函数plogis()这样做。但是仔细阅读?plogis显示,它仍然是基于指数的。
现在,我们可以做非参数近似,而不是使用这些参数近似吗?但是我们不应该在这里做回归,相反,我们想要使用一些精细分辨率精确数据的插值函数来预测pnorm()。嗯,线性插值是最好的选择,因为它是超有效的(由于稀疏性:线性预测矩阵是三对角的)。在R中,approx这样做。我将不熟悉这一点的读者介绍给?approx,我将继续进行。
OP说他只需要标准正态分布,所以我们关注这个问题。考虑以下近似函数(我没有使用approxfun,因为我想要可自定义的h):
approx.pnorm <- function(u, h = 0.2) {
x <- seq(from = -4, to = 4, by = h)
approx(x, pnorm(x), yleft = 0, yright = 1, xout = u)$y
}准确的数据是在一个分辨率h之间的[-4, 4]网格上获取的。低于-4的预测为0,而超出4的预测为1,这满足了CDF的要求。给出了新的u值,在已知精确数据的基础上,用线性插值逼近pnorm(u)。
显然,分辨率h控制精度。考虑计算RMSE和显示近似曲线的下列函数:
RMSEh <- function(h) {
x <- sort(rnorm(1000))
y <- pnorm(x)
y1 <- approx.pnorm(x, h)
plot(x, y, type = "l", lwd = 2); lines(x, y1, col = 2, lwd = 2)
mean((y - y1) ^ 2)^0.5
}
par(mfrow = c(1, 3))
RMSEh(1) # 0.01570339
RMSEh(0.5) # 0.003968882
RMSEh(0.2) # 0.000639888
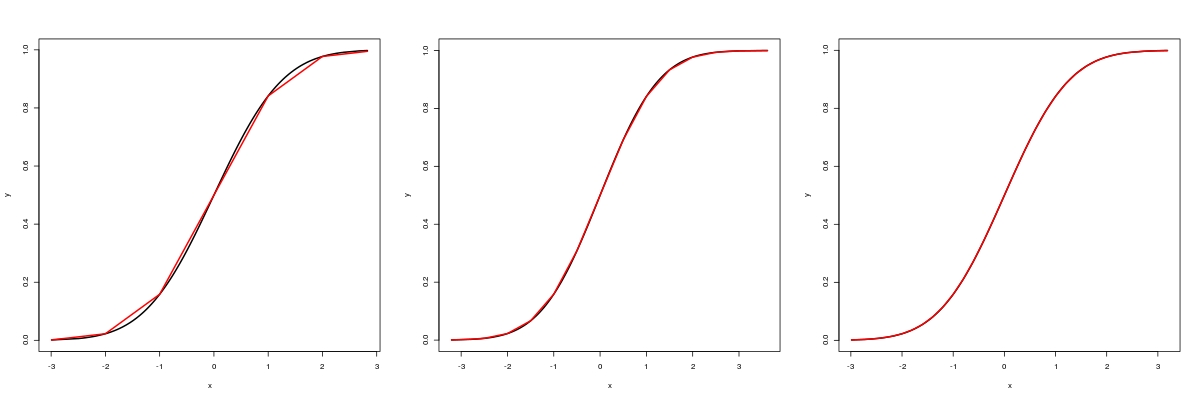
实际上,当h = 0.2,近似已经相当好。因此,我们将在下面使用h = 0.2。
Benchmarking
这应该是最令人兴奋的部分。在上面,我们已经看到,精确计算pnorm(u)需要11秒。现在
system.time(approx.pnorm(u, h = 0.2))
# user system elapsed
# 2.656 0.172 2.833 哇,我们快了近4倍!!
Stack Overflow用户
发布于 2016-06-24 20:16:45
我来这里不是为了让你失望,但是pnorm已经被优化了。如果您在R控制台中键入"pnorm“,您将看到它是如何编写的:
function (q, mean = 0, sd = 1, lower.tail = TRUE, log.p = FALSE)
.Call(C_pnorm, q, mean, sd, lower.tail, log.p)
<bytecode: 0x98712e0>
<environment: namespace:stats>它已经用C编写了(参见Rmath.h)。
有些人可能会建议你做并行计算。例如,r级并行可以使用来自mclapply / parLapply / parSapply包的parallel函数。但是你是否应该这样做取决于你有什么硬件。
在简单的多核机器上并行化pnorm()是个坏主意,因为它是内存绑定的。CPU计算和内存引用的比率是O(1) (使用大的O表示法)。此外,R级并行不是线程级并行,而是通过建立独立的R进程来实现的.这意味着,并行开销更大,不容易摊销。
如果您有一个集群,您可以在不同的节点上进行并行计算,以解决非常大的问题。您将获得良好的并行可伸缩性。
对并行处理的进一步澄清
假设u是一个长向量:u[1], u[2], ....,我们的目标是计算pnorm(u)。每个元素u[i]只从RAM到CPU一次,没有第二次使用。因此,pnorm()的计算需要常量的数据读取。
现在考虑一台具有4个物理CPU的多核计算机(即每个CPU都有非共享执行单元,如寄存器、ALU、FPU、L1缓存等)。我们设置了4个线程或进程,希望在4个不同的pnorm()块上运行4个并行u计算。在计算过程中,每个CPU都“需要数据”,并要求源源不断的数据流。然而,只有一辆公共汽车。如果一个CPU占用了总线,其余三个CPU的数据流就会被切断,因此它们没有什么可做的。换句话说,这4个CPU几乎不可能同时工作,而且它们并不比单CPU计算更好。
现在,我们继续讨论集群上的4个节点。在将初始数据拆分到4个不同的节点后,每个节点将在一个CPU模式下工作。在4个节点之间既没有共享的执行资源,也没有内存资源。它们可以完全平行工作。最后,将4个节点的结果伪造在一起。这样,对于真正的大问题,就可以保证良好/合理的可伸缩性。
多核计算机上的并行计算仅适用于CPU约束的任务(在一定程度上,在总线饱和之前)。具体来说,我们应该使用块算法进行L1缓存。缓存实现了相当大的数据重用。例如,对于块大小为nb的块矩阵乘法,CPU工作与内存读取的比率为O(nb)。这样,在CPU将一块数据读入其独占的L1缓存后,在相对较长的一段时间内(在CPU周期内)它不需要访问RAM,因此总线成为免费的。然后,其他核心可以采取这样的差距/中断来读取他们所需的数据。由于只使用了有限数量的CPU,它们可以在不相互干扰的情况下以交织方式工作。
Stack Overflow用户
发布于 2020-09-21 12:03:50
我感到有点惊讶的是,线性自交显示的在这个答案中是如此缓慢。一种解决方案是使用这个包裹 (由邱一轩创建并由我更新)进行插值。它可以通过调用:
remotes::install_github("boennecd/fastncdf")旧答案的更新版本
下面是我的旧答案,以及使用fastncdf包的新近似。
这里有使用Rcpp的方法吗,还是内置的
pnorm已经被优化了?
你可以用像在这个答案中这样的近似。然而,pnorm似乎确实受益于并行计算,至少在我的机器上是这样。下面是一个使用OpenMP的示例:
#include <Rcpp.h>
#include <Rmath.h>
#include <cmath>
// [[Rcpp::plugins(openmp)]]
#ifdef _OPENMP
#include <omp.h>
#endif
/**
* evaluates the standard normal CDF after avoiding some checks in the
* original version. Use with care!
*/
inline double pnorm_std(double const x, int lower, int is_log) {
if(std::isinf(x) || std::isnan(x))
return NAN;
double p, cp;
p = x;
Rf_pnorm_both(x, &p, &cp, lower ? 0 : 1, is_log);
return lower ? p : cp;
}
/** calls pnorm_std potentially in parallel. */
// [[Rcpp::export(rng = false)]]
Rcpp::NumericVector pnorm_std(Rcpp::NumericVector x,
unsigned const n_threads = 1){
R_len_t const n = x.size();
Rcpp::NumericVector out(n);
double const * const xb = &x[0];
double * const ob = &out[0];
#ifdef _OPENMP
#pragma omp parallel for num_threads(n_threads) schedule(static)
#endif
for(R_len_t i = 0; i < n; ++i)
*(ob + i) = pnorm_std(*(xb + i), 1L, 0L);
return out;
}使用上面的Rcpp::sourceCpp,我们现在可以比较计算时间和精度/得到相同的结果:
# simulate data
set.seed(1)
u <- rnorm(1e7)
# assign function to compare with from other answer
approx_pnorm <- function(u, h = 0.2) {
x <- seq(from = -4, to = 4, by = h)
approx(x, pnorm(x), yleft = 0, yright = 1, xout = u)$y
}
# check times and results. First using the new interpolation method
library(fastncdf)
system.time(lin_itr <- fastpnorm(u))
#R> user system elapsed
#R> 0.068 0.016 0.084
# w/ pre-allocated vector
dum <- rep(0., length(u))
system.time(fastpnorm_preallocated(u, p = dum))
all.equal(lin_itr, dum)
#R> user system elapsed
#R> 0.058 0.000 0.058
# then as in the original answer
system.time(truth <- pnorm(u))
#R> user system elapsed
#R> 0.368 0.008 0.376
system.time(mini_one <- pnorm_std(u, 1L))
#R> user system elapsed
#R> 0.265 0.016 0.281
system.time(mini_six <- pnorm_std(u, 4L))
#R> user system elapsed
#R> 0.265 0.024 0.092
system.time(other_ans <- approx_pnorm(u, h = 0.2))
#R> user system elapsed
#R> 0.272 0.004 0.277
# are the results identical?
all.equal(mini_one, truth)
#R> [1] TRUE
all.equal(other_ans, truth)
#R> [1] "Mean relative difference: 0.001062221"
all.equal(lin_itr, truth)
#R> [1] "Mean relative difference: 8.765925e-08"
# what about the times?
bench::mark(`R ` = pnorm (u),
`C++ (1 thread) ` = pnorm_std (u, 1L),
`C++ (2 threads) ` = pnorm_std (u, 2L),
`C++ (4 threads) ` = pnorm_std (u, 4L),
`C++ (6 threads) ` = pnorm_std (u, 6L),
`Other answer ` = approx_pnorm(u, h = 0.2),
`C++ interpolation` = fastpnorm (u),
min_time = 10, relative = TRUE, check = FALSE)
#R> # A tibble: 7 x 13
#R> expression min median `itr/sec` mem_alloc `gc/sec` n_itr n_gc total_time result memory time gc
#R> <bch:expr> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <dbl> <bch:tm> <list> <list> <list> <list>
#R> 1 R 5.23 5.01 1 1 1.33 21 6 7.84s <NULL> <Rprofmem[,3] [1 × 3]> <bch:tm [27]> <tibble [27 × 3]>
#R> 2 C++ (1 thread) 3.96 3.82 1.31 1 1.53 28 7 7.95s <NULL> <Rprofmem[,3] [1 × 3]> <bch:tm [35]> <tibble [35 × 3]>
#R> 3 C++ (2 threads) 2.18 2.10 2.39 1 2.06 54 10 8.43s <NULL> <Rprofmem[,3] [1 × 3]> <bch:tm [64]> <tibble [64 × 3]>
#R> 4 C++ (4 threads) 1.29 1.26 3.98 1 2.62 92 13 8.63s <NULL> <Rprofmem[,3] [1 × 3]> <bch:tm [105]> <tibble [105 × 3]>
#R> 5 C++ (6 threads) 1 1 5.01 1 3.48 114 17 8.49s <NULL> <Rprofmem[,3] [1 × 3]> <bch:tm [131]> <tibble [131 × 3]>
#R> 6 Other answer 3.86 3.76 1.33 1.00 1 31 5 8.68s <NULL> <Rprofmem[,3] [11 × 3]> <bch:tm [36]> <tibble [36 × 3]>
#R> 7 C++ interpolation 1.13 1.08 4.61 1 3.07 105 15 8.49s <NULL> <Rprofmem[,3] [1 × 3]> <bch:tm [120]> <tibble [120 × 3]>在我的六台核心机器上,使用六个线程可以减少五倍的计算时间。显然,它并不是线性的。此外,我前面提到的答案是没有产生7,000万变量的大幅度减少,也没有那么精确(我希望我没有犯错误)。新的C++版本与使用Rcpp解决方案的6个线程一样快。
https://stackoverflow.com/questions/38008696
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号