
带宽的nvprof选项
使用命令行的nvprof -度量标准测量带宽的正确选项是什么?我使用flop_dp_efficiency来获取峰值触发器的百分比,但是在手册中似乎有很多测量带宽的选项,但我并不真正理解我正在测量的是什么。在我看来,dram_read,dram_write,gld_read,gld_write都是一样的。此外,我是否应该假设两者同时发生,从而将bandwdith报告为read+write吞吐量的总和?
编辑:
根据图表的最佳答案,从设备内存到内核的带宽是多少?我正在考虑从内核到设备内存的路径上的最小带宽(read+write),这很可能是拖到L2缓存的。
我试图通过测量触发器和带宽来确定内核是计算的还是内存的。
回答 1
Stack Overflow用户
发布于 2016-06-10 04:49:47
为了理解这方面的分析器度量,有必要了解GPU中的内存模型。我发现在Nsight Visual Studio版本文档中发布的图表很有用。我已经用编号箭头标记了图表,这些箭头引用了我在下面列出的编号度量(和传输方向):
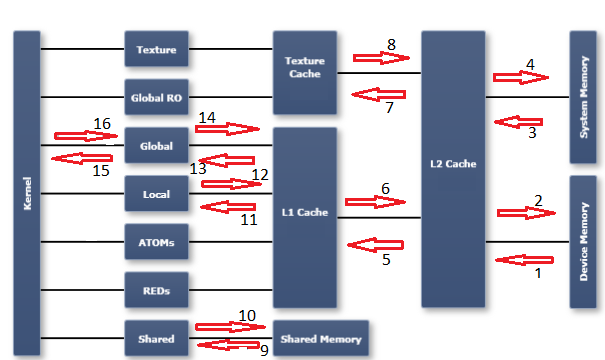
有关每个度量的描述,请参阅CUDA分析器指标参考:
- dram_read_throughput,dram_read_transactions
- dram_write_throughput,dram_write_transactions
- sysmem_read_throughput,sysmem_read_transactions
- sysmem_write_throughput,sysmem_write_transactions
- l2_l1_read_transactions,l2_l1_read_throughput
- l2_l1_write_transactions,l2_l1_write_throughput
- l2_tex_read_transactions,l2_texture_read_throughput
- 纹理是只读的,在此路径上不可能进行任何事务处理。
- shared_load_throughput,shared_load_transactions
- shared_store_throughput,shared_store_transactions
- l1_cache_local_hit_rate
- l1是贯穿缓存的,因此对于这个路径没有(独立的)度量,请参考其他本地度量。
- l1_cache_global_hit_rate
- 见注12
- gld_efficiency,gld_throughput,gld_transactions
- gst_efficiency,gst_throughput,gst_transactions
备注:
- 从右到左的箭头指示读取活动。从左到右的箭头指示写活动。
- “全局”是一个合乎逻辑的空间。从程序员的角度来看,它指的是逻辑地址空间。指向“全局”空间的事务可能以缓存、sysmem或设备内存(dram)中的一个缓存结束。另一方面,"dram“是一个物理实体(例如L1和L2缓存)。“逻辑空间”都是在图的第一列中描述的,紧靠在“内核”列的右边。右边的其余列是物理实体或资源。
- 我没有尝试用图表上的位置标记每一个可能的内存度量。希望这个图表将是有教育意义的,如果你需要找出其他。
有了上面的描述,你的问题可能还没有得到回答。然后,你就有必要澄清你的要求--“你想准确地衡量什么?”但是,根据您编写的问题,如果您关心的是实际消耗的内存带宽,那么您可能希望查看dram_xxx指标。
另外,如果您只是试图获得最大可用内存带宽的估计值,那么使用CUDA示例代码bandwidthTest可能是获得该数据的代理度量的最简单方法。只需使用所报告的设备的设备带宽编号,作为对您的代码可用的最大内存带宽的估计。
结合上述思想,dram_utilization度量提供了一个缩放的结果,表示实际使用的总可用内存带宽的一部分(从0到10)。
https://stackoverflow.com/questions/37732735
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号