
arima()函数在R中的计算复杂度是多少?
如果我的时间序列有n成员,并且我想拟合ARIMA(1,0,1)模型,那么大O表示法的复杂性是什么?
在下面的示例中,我需要知道第二行代码的复杂性:
series <- arima.sim(list(order=c(1,0,1), ar=.9, ma=-.5), n=1000)
result <- arima(series, order=c(1,0,1))谢谢。
回答 1
Stack Overflow用户
发布于 2016-06-08 18:43:47
这是O(n)的复杂性。关于这个的故事?见下文。
正如我在评论中所说,我们可以用回归模型来衡量它。作为一个玩具演示,请考虑以下数据收集和回归过程。
我们首先定义一个函数来度量ARMA(1,1)模型(或ARIMA(1,0,1))的模型拟合时间。(请注意,这里使用的是基本的system.time()。您可以考虑使用包microbenchmark() microbenchmark__。但在下面,我将使用相当大的n__,以降低时间测量的灵敏度。)
t_arma <- function(N) {
series <- arima.sim(list(order=c(1,0,1), ar=.9, ma=-.5), n=N)
as.numeric((system.time(arima(series, order=c(1,0,1)))))[3]
}我们需要收集数据,比如说100。我们尝试了100个越来越大的n,并测量了模型拟合时间t。
k <- 100; t <- numeric(k)
n <- seq(20000, by = 1000, length = k) ## start from n = 20000 (big enough)
for (i in 1:k) t[i] <- t_arma(n[i])现在,如果我们假设复杂性是:a * (n ^ b),或者O(n ^ b),我们可以通过一个回归模型来估计a,b:
log(t) ~ log(a) + b * log(n)我们特别感兴趣的是斜率估计:b。
所以让我们打电话给lm()
fit <- lm(log(t) ~ log(n))
#Coefficients:
#(Intercept) log(n)
# -9.2185 0.8646 我们还可以勾勒出log(n) v.s. log(t)的散点图,以及贴合的线条:
plot(log(n), log(t), main = "scatter plot")
lines(log(n), fit$fitted, col = 2, lwd = 2)
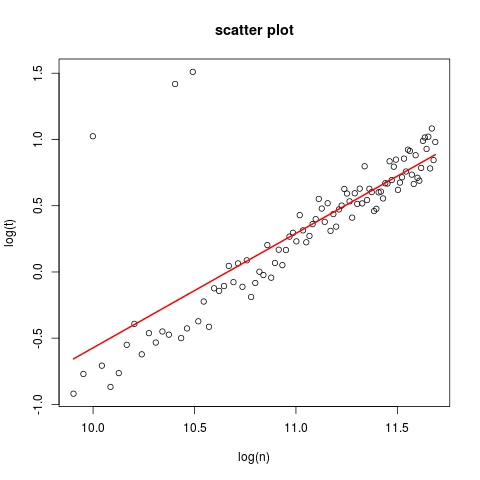
一开始有一些离群点,因此斜率比它应该的要低。为了增强健壮性,我们现在考虑删除异常值和修改模型。
离群点具有较大的残差。让我们看看:
plot(fit$resi, main = "residuals")
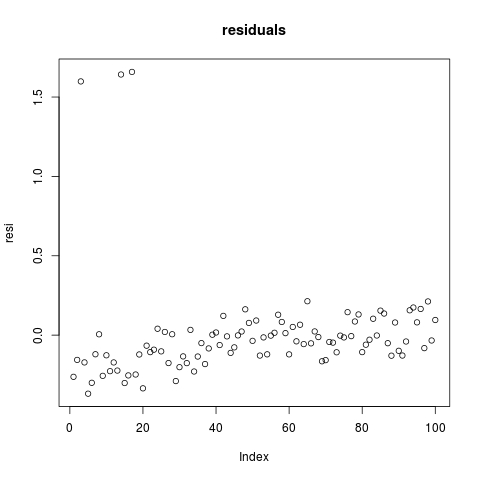
我们可以标记和移除那些离群点。看起来0.5是一个足够好的阈值来过滤那些异常值。
exclude <- fit$resi > 0.5
n <- n[!exclude]
t <- t[!exclude]现在,我们重新定义线性模型,并绘制出如下图:
robust_fit <- lm(log(t) ~ log(n))
#Coefficients:
#(Intercept) log(n)
# -11.197 1.039
plot(log(n), log(t), main = "scatter plot (outliers removed)")
lines(log(n), robust_fit$fitted, col = 2, lwd = 2)
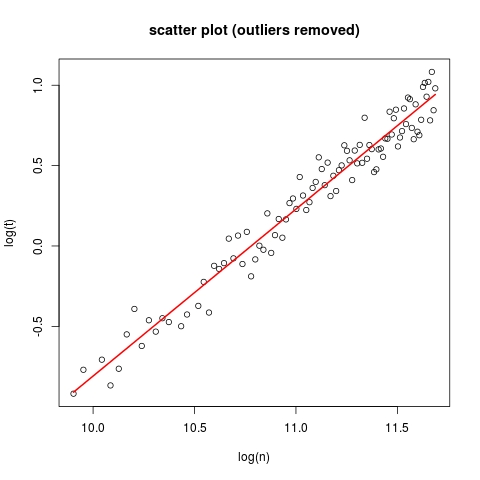
哇,太好了,我们太棒了!斜率估计为1,因此O(n)复杂度是合理的!
https://stackoverflow.com/questions/37709751
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号