
Lavaan - CFA -分类变量-最后一个阈值是奇怪的
我想用lavaan在R中执行多个组CFA。
我有几个范畴变量,有些变量包含11个类别。因此,这些变量将有10个阈值。在下面的结果中,你可以看到第10个阈值比第9个阈值小,也就是说,它不是在折皱的顺序。
有11个类别的多个变量也有相同的问题。
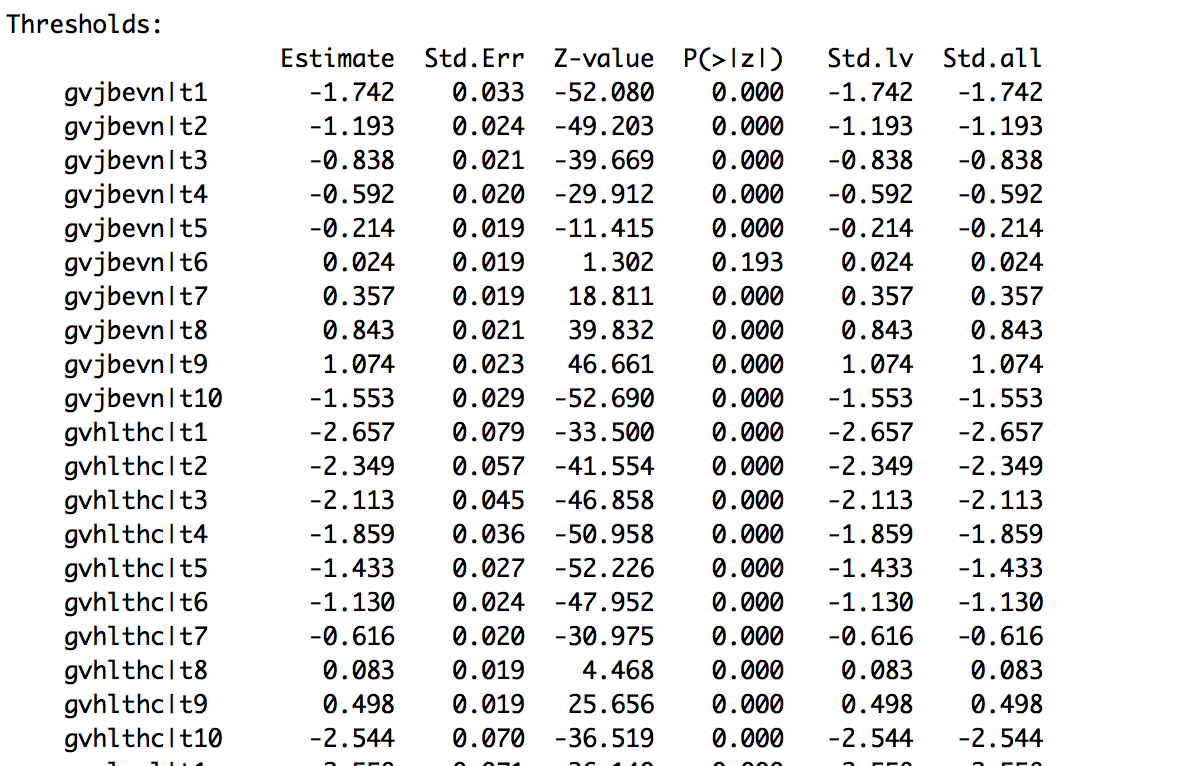
问题:
为什么门槛会被扭曲?
R码:
model2<-'range = ~ NA*gvjbevn + gvhlthc + gvslvol + gvslvue + gvcldcr + gvpdlwk
goals = ~ NA*sbprvpv + sbeqsoc + sbcwkfm
range~~1*range
goals~~1*goals
gvhlthc ~~ gvslvol
gvcldcr ~~ gvpdlwk
'
cfa.model2<-cfa(model2, ordered=varcat, estimator="WLSMV",data=sub)
summary(cfa.model2,fit.measures=TRUE,standardized=TRUE, modindices=TRUE)回答 2
Stack Overflow用户
发布于 2019-04-25 18:46:51
对阈值的标签分配按字母顺序排序,也称为c('t1','t10','t2','t3'....),但summary()将其排序为“正确”。
您可以尝试添加其他因素,以检查您的比例是否对应于:
c('t1','t10','t11','t12',...,'t2','t3'....)除了了解哪一行是您的每个因素之外,您可以做的事情不多。
Stack Overflow用户
发布于 2017-12-19 11:38:12
好吧,我似乎因为没有足够的声誉而不能补充评论,所以我只能回答,虽然这不是一个正确的答案(这肯定解决不了你的问题,虽然我希望它指向正确的方向)。
为了使您的示例具有可重现性,您应该向社区提供符合模型的数据。
另一方面,我猜你的问题肯定与这个类别的性质有关:你的第11个类别可能并不意味着对这个项目的“最一致的程度”,或者反应类别不是从1到11,或者类似的东西。考虑到其余的阈值似乎准确地代表了一个连续的单调增长的尺度,而且同样的问题精确地发生在不同变量中的同一类别中(至少是您正在显示的两个变量),那么在这些项目中肯定有一个具有响应尺度的东西。
总之,这似乎是一个解释模型参数的问题,而不是一个统计问题。
https://stackoverflow.com/questions/37703789
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号