
二层神经网络中权值的更新
我试图使用类似于此的神经网络来模拟异或门:
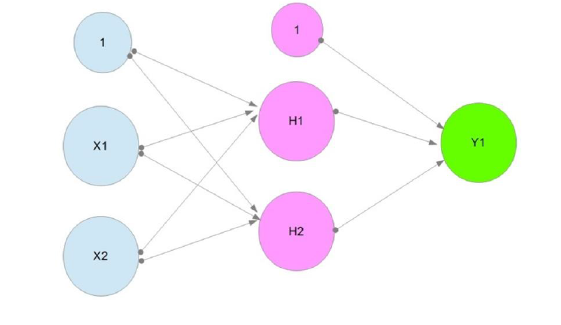
现在我了解到每个神经元都有一定的权重和偏倚。我使用一个sigmoid函数来确定神经元是否应该在每一种状态下触发(因为这使用的是乙状结肠而不是阶跃函数,所以我使用的是松散的触发,因为它实际上显示了真值)。
我成功地对饲料转发部分进行了仿真,现在我想使用反向传播算法更新权重并对模型进行训练。问题是,对于x1和x2的每个值,都有一个单独的结果(总共有4个不同的组合),在不同的输入对下,可以计算出不同的错误距离(期望输出和实际结果之间的差异),并最终实现不同的权重更新。这意味着我们将得到4组不同的权重更新,每个独立的输入对使用反向传播。
我们应该如何决定正确的重量更新?
假设我们对一个输入对重复反向传播,直到我们收敛为止,但是如果我们选择另一对输入,那么如果我们会收敛到一个不同的权值集呢?
回答 1
Stack Overflow用户
发布于 2016-06-05 20:57:36
现在我知道每个神经元都有一定的权重。我使用乙状结肠函数来确定神经元是否在每一种状态下都会触发。
你并不是真的“决定”这个,典型的MLP不做“火”,他们输出的是真实值。有些神经网络实际上会触发(比如RBM),但这是一个完全不同的模型。
这意味着我们将得到4组不同的权值更新,每个输入对使用反向传播。
这实际上是,一个特性。让我们从乞讨开始。您尝试将整个培训集(在您的例子中是-4个示例)中的一些损失函数降到最低,它的形式如下:
L(theta) = SUM_i l(f(x_i), y_i)其中l是一些损失函数,f(x_i)是您当前的预测和y_i的真值。你用梯度下降来做这件事,因此你试图计算L的梯度,并与它相反。
grad L(theta) = grad SUM_i l(f(x_i), y_i) = SUM_i grad l(f(x_i), y_i)您现在所称的“单个更新”是针对单个训练对grad l(f(x_i) y_i)的(x_i, y_i)。通常您不会使用这个方法,而是使用和(或平均)在整个 dataset中进行更新,因为这是真正的梯度。然而,在实践中,这可能是不可行的(训练集通常是相当大的),而且从经验上看,训练中更多的“噪音”通常更好。因此,出现了另一种学习技术,称为随机梯度下降,简而言之,它表明在一些简单的假设下(如加性损失函数等)。你实际上可以独立地做你的“小更新”,你仍然会收敛到局部极小值!换句话说,你可以按随机顺序做你的更新“点式”,你仍然会学习。会不会永远是同一种解决办法?不是的。但是对于计算非凸函数的整体梯度优化也是如此--非凸函数的梯度优化几乎总是不确定的(您可以找到一些局部解,而不是全局解)。
https://stackoverflow.com/questions/37646589
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号