
什么意味着原子分组会出现更快的故障?
注意事项 :-这个问题是有点长,因为它包括一个章节从书。
给出了atomic groups导致更快的故障。引用书中的那一节
使用原子分组更快的失败。认为
^\w+:应用于Subject。我们可以看到,只要看一下它,它就会失败,因为文本中没有冒号,但是regex引擎只有通过检查的动作才能得出这个结论。 因此,当第一次检查:时,\w+将已经前进到字符串的末尾。这导致了许多状态--每个\w匹配的加号都有一个\w状态(除了第一个,因为plus需要一个匹配)。当在字符串末尾选中时,:会失败,因此regex引擎返回到最近保存的状态:
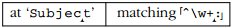
此时,:再次失败,这一次试图匹配t。这种回溯-测试失败循环一直持续到最古老的状态:
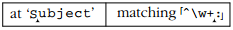
在最终状态的尝试失败后,最终可以宣布总体失败。所有这些回溯都是大量的工作,仅仅看一眼我们就知道是不必要的。如果冒号在最后一个字母之后不能匹配,它肯定不能匹配+被迫放弃的一个字母!
因此,知道\w+留下的任何状态,一旦完成,都可能导致匹配,所以我们可以为regex引擎省去检查它们的麻烦:^(?>\w+):。通过添加原子分组,我们使用正则表达式的全局知识,通过丢弃保存的状态(我们知道这是无用的)来增强\w+的本地工作。如果有匹配,原子分组就不重要了,但是如果没有匹配,丢弃无用的状态让正则表达式更快地得出结论。
我试过这些regex 这里。它对^\w+:执行了4个步骤,对^(?>\w+): 执行了6个步骤(禁用了内部引擎优化)
我的问题
- 上文第二段提到,
因此,当第一次检查
:时,\w+将已经前进到字符串的末尾。这会导致很多状态--每个\w匹配的一个跳过me状态(除了第一个,因为加号需要一个匹配),然后在字符串末尾检查.When,:失败,因此regex引擎返回到最近保存的状态:
此时,:再次失败,这一次试图匹配t。这种回溯-测试失败循环一直持续到最古老的状态:
但在这网站上,我没有看到任何回溯。为什么?
内部是否正在进行一些优化(即使在禁用之后)?
- 一个regex所采取的步骤数量是否决定一个regex是否比其他regex具有良好的性能?
回答 1
Stack Overflow用户
发布于 2016-05-16 12:19:31
该站点上的调试器似乎掩盖了回溯的细节。RegexBuddy做得更好。下面是它为^\w+:显示的内容
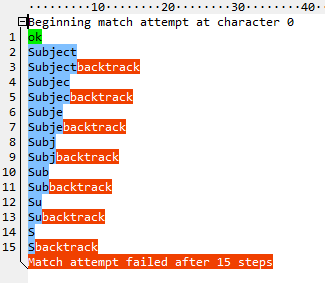
在\w+使用完所有字母后,它会尝试匹配:并失败。然后,它返回一个字符,再次尝试:,然后再次失败。以此类推,直到没有什么东西可以归还。一共十五步。现在看看原子版本(^(?>\w+):):
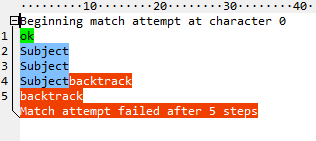
在第一次与:不匹配后,它立即将所有的字母返回,就好像它们是一个字符一样。总共有五个步骤,其中两个正在进入和离开小组。使用拥有式量词(^\w++:)甚至可以消除以下情况:
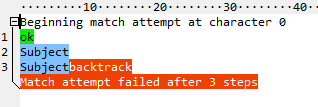
至于您的第二个问题,是的,regex调试器的步数度量是有用的,特别是如果您只是在学习regexes。每个regex版本至少有几个优化,允许即使编写得不好的正则表达式也能充分地执行,但是调试器(特别是与版本无关的调试器,比如RegexBuddy)可以在您做错事时清楚地显示出来。
https://stackoverflow.com/questions/37251809
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号