
循环中的Numpy点
循环中的Numpy点
提问于 2016-05-14 15:24:25
在下面的代码中,我使用numpy.dot来加快计算速度。
u = numpy.zeros((l, l))
wp = numpy.zeros((l,2))
# some code which edits u and wp
for x in range(N):
wavg = numpy.dot(wp[:, 0], wp[:, 1])
wp[:, 0] = 1.0/wavg*numpy.dot(u, numpy.multiply(wp[:, 0], wp[:, 1]))对于小l,最慢的部分是外循环。现在我问自己有没有办法摆脱这个循环?
编辑:用数学术语来说,这段代码如下所示
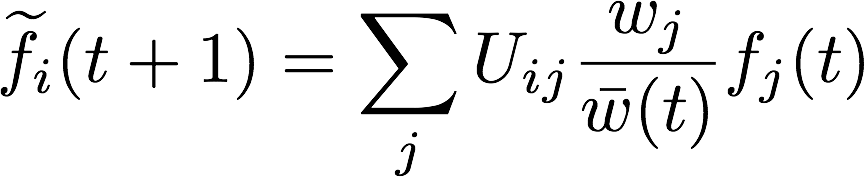
回答 2
Stack Overflow用户
回答已采纳
发布于 2016-05-14 16:17:51
通过预先计算一项来进行的小改进
u = np.zeros((l, l))
wp = np.zeros((l,2))
# some code which edits u and wp
m = u*wp[:, 1]
for x in range(N):
wavg = np.dot(wp[:, 0], wp[:, 1])
wp[:, 0] = 1.0/wavg*np.dot(m, wp[:, 0])但是我们可以做得更好--而不是每次计算平均值,我们可以在最后一次迭代中完成:
m = u*wp[:, 1]
for x in range(N - 1):
wp[:, 0] = np.dot(m, wp[:, 0])
wavg = np.dot(wp[:, 0], wp[:, 1])
wp[:, 0] = 1.0/wavg*np.dot(m, wp[:, 0])但是还有一件事我们可以做--这个循环可以用矩阵指数来代替:
m = u*wp[:, 1]
wp[:, 0] = np.linalg.matrix_power(m, N-1).dot(wp[:, 0])
wavg = np.dot(wp[:, 0], wp[:, 1])
wp[:, 0] = 1.0/wavg*np.dot(m, wp[:, 0])不幸的是,这似乎要慢得多。但是,如果您可以预先计算np.linalg.matrix_power(m, N-1),那么它就会更快
Stack Overflow用户
发布于 2016-05-14 16:17:28
我仍然对数组的形状以及代码和方程之间的关系感到困惑。
但只要看一下这个方程,我认为它可以计算为:
In [515]: n,m = 3,4
In [516]: U = np.ones((n,m))
In [517]: w = np.ones((m,))
In [518]: f = np.ones((m,))
In [519]: np.einsum('ij,j,j->i',U,w,f)
Out[519]: array([ 4., 4., 4.])目前,我关心的是如何使尺寸匹配,而不是在最终值上。计算非常简单,不需要爱因斯坦表示法,但是einsum使翻译几乎是机械的。
dot等效为
In [520]: np.dot(U, w*f)
Out[520]: array([ 4., 4., 4.])由于随着时间的推移,迭代的f (取决于前一个值(以及这个外部值w(t))的值),很难删除该循环;我们只需使内容更快。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/37228439
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号