
星星之火不使用纱线集群资源
我试图在Hadoop集群(2.4.2)上使用Spark (1.6.1)运行Python脚本。集群是使用Ambari (2.2.1.1)安装、配置和管理的。
我有一个由4个节点组成的集群(每个40 of HD-8核-16 of)。
我的脚本使用sklearn库:因此为了在spark上并行化,我使用了spark_sklearn库(参见https://databricks.com/blog/2016/02/08/auto-scaling-scikit-learn-with-spark.html)。
此时,我尝试使用以下方法运行脚本:
spark-submit spark_example.py --master yarn --deploy-mode client --num-executors 8 --num-executor-core 4 --executor-memory 2G但是它总是在本地主机上运行,只有一个执行器。
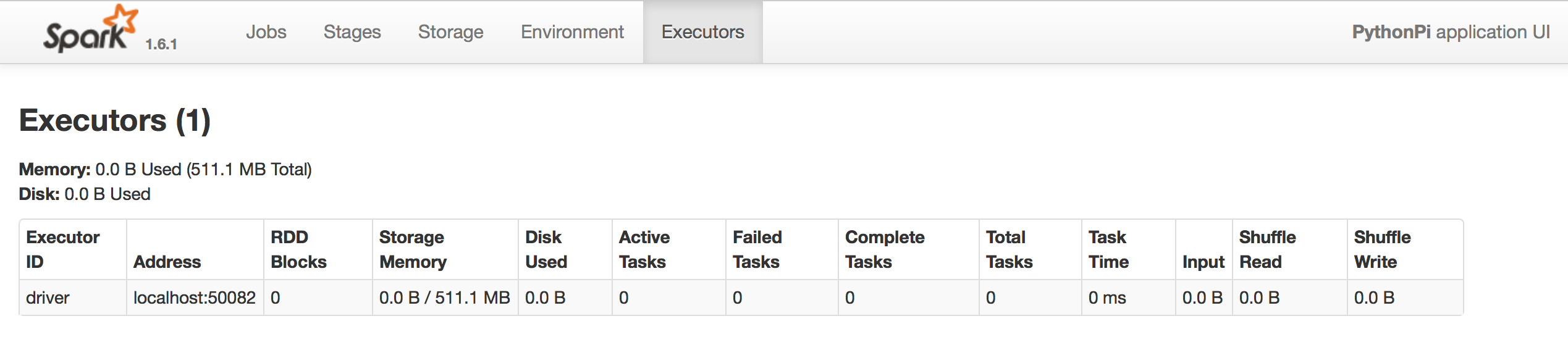
在Ambari仪表板上,我还可以看到集群中只有一个节点是资源消耗的。并且尝试不同的配置(执行器、核心),执行时间是相同的。
更新
这是Yarn UI节点屏幕截图:
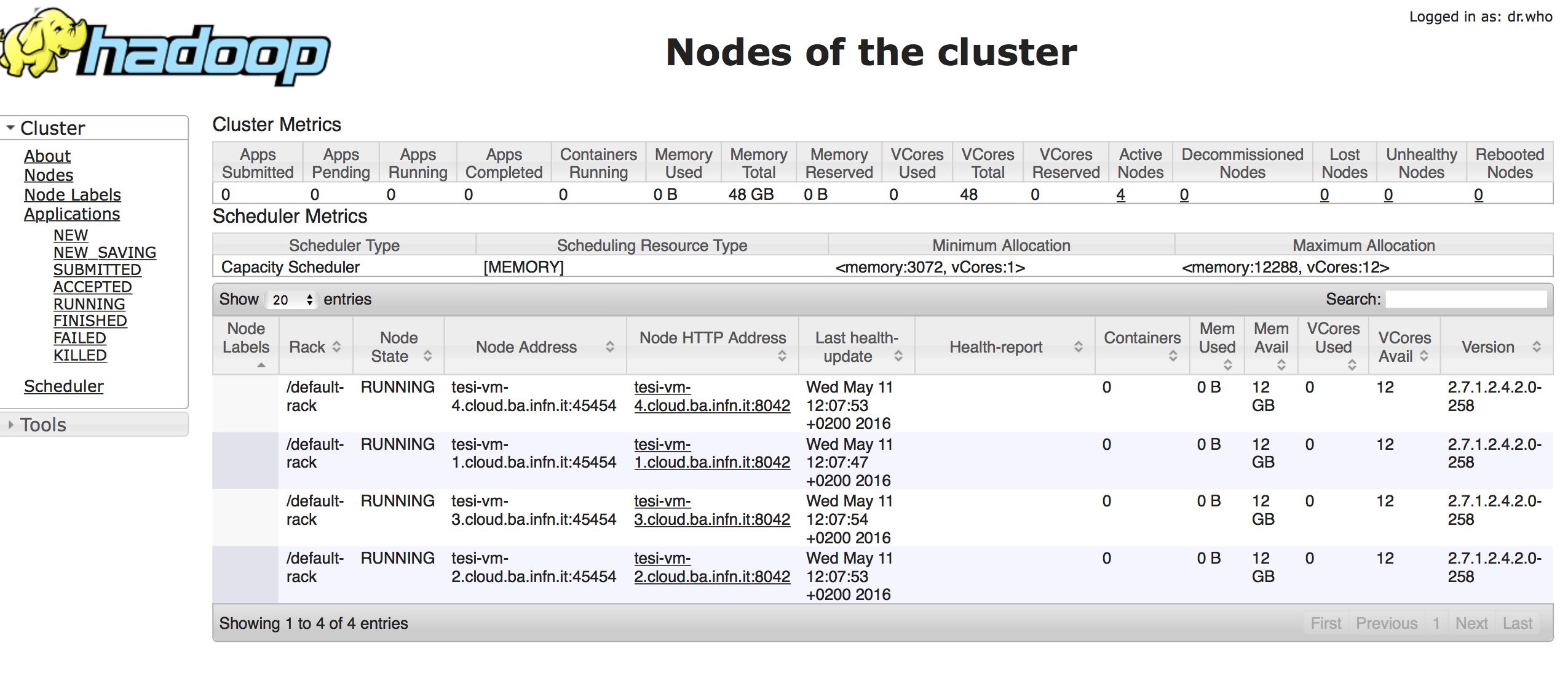
这是Scheduler Tab
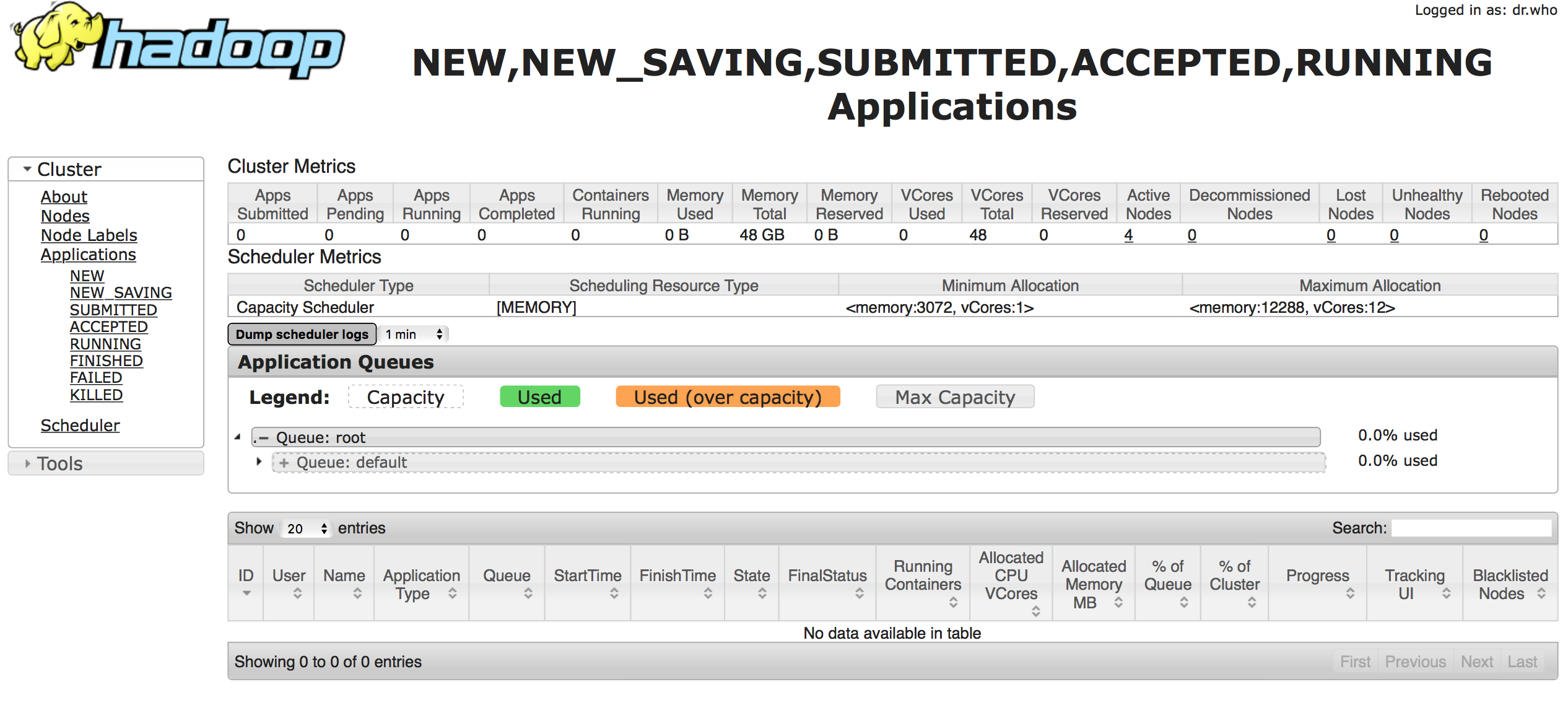
有什么想法吗?
非常感谢
回答 1
Stack Overflow用户
发布于 2016-05-12 08:48:21
我会在霍顿工作社区。上回答同样的问题
设置参数MASTER="yarn-cluster" (或MASTER="yarn-client")似乎有效:现在我在Spark和Spark中看到了应用程序报告。
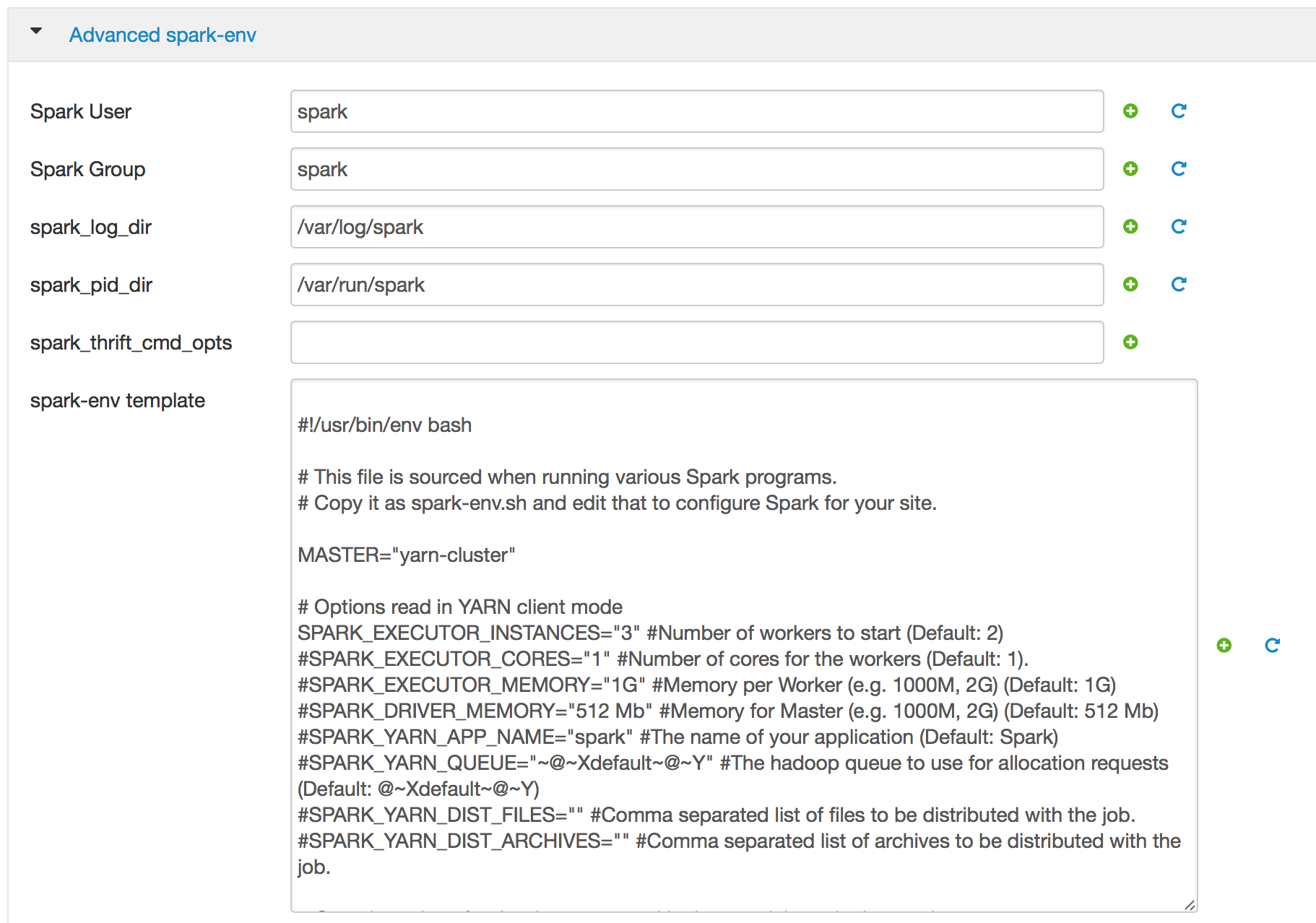
ps:似乎没有考虑通过命令行传递的参数(例如:--num-executors 8--num-executor-core 4--executor-memory 2G)。相反,如果我在安巴里的“”字段中设置了执行器param,则将考虑这些参数。无论如何,它现在起作用了:)
我希望这对将来的人有帮助。
https://stackoverflow.com/questions/37159054
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号