
R中数据清洗的可能解决方案
R中数据清洗的可能解决方案
提问于 2016-05-08 11:02:55
我有一个数据集,其中包含两个日期和时间列。我想在同一行中对齐日期和时间列,如果第二个日期和时间列不匹配,则删除第二个日期和时间列右侧的所有内容。我的数据集问题的示例如下所示。

注意时间1!=时间。经过清理的数据集最终版本如下所示:
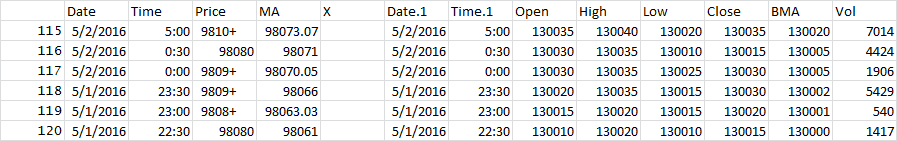
我想删除Date.1列右边的所有内容,直到Date.1=Date和Time.1=Time为止。
为此,我编写了以下R代码:
rm(list = ls())
data<-read.csv(file="data.csv",header=T,stringsAsFactors=FALSE)
datacol<-ncol(data)
datarow<-nrow(data)
for (i in 1:datarow){
for (j in 1:(datarow-1)){
while(data$Date[i]!=data$Date.1[j] | data$Time[i]!=data$Time.1[j]){data[j,6:datacol]<-data[j+1,6:datacol];
if (j<datarow) next; if (j == datarow) break; print(data[i,]);}
}
}但是,即使我在满足行的长度时指定了中断,但R仍然没有停止地运行。我希望就如何解决这一问题提出任何建议。
谢谢。
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-05-08 17:16:09
考虑按列设置子集,然后合并您的数据集而不需要嵌套的for循环。下面以填充的值再现数据,以供演示:
df <- read.table(text="Date Time Price MA X Date.1 Time.1 Open High Low Close BMA Vol
5/2/2016 5:00 9810+ 98073.07 NA 5/2/2016 5:00 130035 130040 130020 130035 130020 7014
5/2/2016 0:30 98080 98071 NA 5/2/2016 4:30 130030 130035 130020 130035 130017 6631
5/2/2016 0:00 9809+ 98070.05 NA 5/2/2016 4:00 130030 130035 130020 130030 130016 2465
5/1/2016 23:30 9809+ 98066 NA 5/2/2016 3:30 130025 130035 130020 130030 130015 2918
5/1/2016 23:00 9809+ 98063.03 NA 5/2/2016 3:00 130030 130030 130020 130020 130012 2289
5/1/2016 22:30 98080 98061 NA 5/2/2016 2:30 130035 130035 130030 130030 130010 4699
5/3/2016 12:30 7777 7777 NA 5/2/2016 0:30 130030 130035 130010 130015 130005 4424
5/3/2016 12:45 8888 8888 NA 5/2/2016 0:00 130030 130035 130025 130030 130005 1906
5/4/2016 13:30 78787 78787 NA 5/1/2016 23:30 130020 130035 130015 130030 130002 5429
5/4/2016 13:45 87878 87878 NA 5/1/2016 23:00 130015 130020 130015 130020 130001 540
5/4/2016 13:50 77888 88777 NA 5/1/2016 22:30 130010 130020 130010 130015 130000 1417
", header = TRUE)
# SUBSET INTO TWO SEPARATE DFs
df1 <- df[c('Date', 'Time', 'Price', 'MA', 'X')]
df2 <- df[c('Date.1', 'Time.1', 'Open', 'High', 'Low', 'Close', 'BMA', 'Vol')]
# MERGE BY DATE AND TIME COLUMNS
# (NOTE: LOSE SECOND PAIR OF JOIN VARS --Date.1, Time.1-- WITH DF SORT)
finaldf <- merge(df1, df2, by.x = c('Date', 'Time'), by.y = c('Date.1', 'Time.1'))
finaldf
# Date Time Price MA X Open High Low Close BMA Vol
# 1 5/1/2016 22:30 98080 98061.00 NA 130010 130020 130010 130015 130000 1417
# 2 5/1/2016 23:00 9809+ 98063.03 NA 130015 130020 130015 130020 130001 540
# 3 5/1/2016 23:30 9809+ 98066.00 NA 130020 130035 130015 130030 130002 5429
# 4 5/2/2016 0:00 9809+ 98070.05 NA 130030 130035 130025 130030 130005 1906
# 5 5/2/2016 0:30 98080 98071.00 NA 130030 130035 130010 130015 130005 4424
# 6 5/2/2016 5:00 9810+ 98073.07 NA 130035 130040 130020 130035 130020 7014页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/37099058
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号