
当某些子区间的结果已知时,如何有效地迭代
您的函数总是输入一个间隔(在本例中为自然数),此函数返回一个结果,但在处理器上花费很大,在本例中由have模拟:
function calculate($start, $end) {
$result = 0;
for($x=$start;$x<=$end;$x++) {
$result++;
usleep(250000);
}
return $result;
}为了提高效率,有一个旧的结果数组,它包含使用的区间--该区间的函数的结果:
$oldResults = [
['s'=>1, 'e'=>2, 'r' => 1],
['s'=>2, 'e'=>6, 'r' => 4],
['s'=>4, 'e'=>7, 'r' => 3]
];如果我调用calculate(1,10),函数应该能够根据旧的结果计算新的间隔并累积它们,在这种特殊情况下,它应该将旧的结果从1添加到2,把旧的结果从2添加到6,并做一个新的calculate(6,10)并添加它。考虑到函数忽略了从4到7的旧保存间隔,因为使用2-6更方便。
这是对问题的可视化表示:
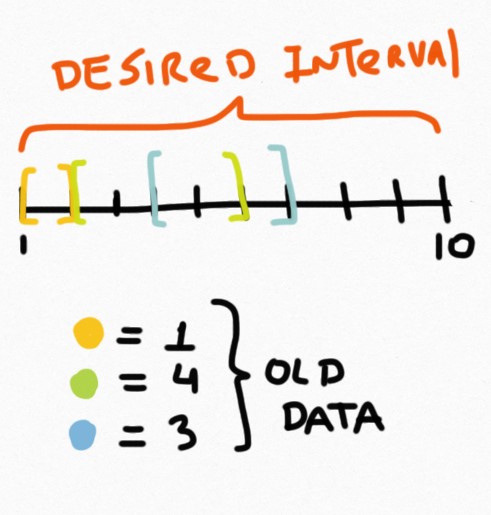
当然,在这个例子中,calculate()非常简单,您可以找到解决这个问题的特殊方法,但是在真正的代码中,calculate()很复杂,我唯一知道的就是calculate(n0,n3)==calculate(n0,n1)+calculate(n1,n2)+calculate(n2,n3)。
如果不使用一组IF和foreach,我就无法找到解决旧数据重用的方法,我相信有一种更优雅的方法来解决这个问题。
你可以玩代码在这里。
注意:我使用PHP,但我可以阅读JS、Pyton、C和类似的语言。
回答 2
Stack Overflow用户
发布于 2016-05-03 15:35:10
如果您确定是calculate(n0,n3)==calculate(n0,n1)+calculate(n1,n2)+calculate(n2,n3),那么在我看来,一种方法可能只是建立一个数据库缓存。
您可以预先计算每个离散间隔,并将其结果存储在记录中。
$start = 0;
$end = 1000;
for($i=1;$i<=$end;$i++) {
$result = calculate($start, $i);
$sql = "INSERT INTO calculated_cache (start, end, result) VALUES ($start,$i,$result)";
// execute statement via whatever dbms api
$start++;
}现在,每当有新的请求出现时,数据库查找就会大大加快。注意,在这个粗略的例子中,您可能需要修改我的边界情况。
function fetch_calculated_cache($start, $end) {
$sql = "
SELECT SUM(result)
FROM calculated_cache
WHERE (start BETWEEN $start AND $end)
AND (end BETWEEN $start AND $end)
";
$result = // whatever dbms api you chose
return $result;
}有几个明显的考虑因素,例如:
- 缓存失效您的
calculate函数的结果多久会改变一次?然后,您需要重新填充数据库。 - 您想要存储多少时间间隔?在我的例子中,我任意选择1000
- 您是否需要检索非顺序的间隔结果?您需要将上述过程以块的形式应用。
Stack Overflow用户
发布于 2016-05-03 15:56:40
我写了这个:
function findFittingFromCache($from, $to, $cache){
//length for measuring usefulnes of chunk from cache (now 0.1 means 10% percent of total length)
$totalLength = abs($to - $from);
$candidates = array_filter($cache, function($val) use ($from, $to, $totalLength){
$chunkLength = abs($val['e'] - $val['s']);
if($from <= $val['s'] && $to >= $val['e'] && ($chunkLength/$totalLength > 0.1)){
return true;
}
return false;
});
//sorting to have non-decremental values of $x['s']
usort($candidates, function($a, $b){ return $a['s'] - $b['s']; });
$flowCheck = $from;
$needToCompute = array();
foreach($candidates as $key => $val){
if($val['s'] < $flowCheck){
//already using something with this interval
unset($candidates[$key]);
} else {
if($val['s'] > $flowCheck){
//save what will be needed to compute
$needToCompute[] = array('s'=>$flowCheck, 'e'=>$val['s']);
}
//increase starting position for next loop
$flowCheck = $val['e'];
}
}
//rest needs to be computed as well
if($flowCheck < $to){
$needToCompute[] = array('s'=>$flowCheck, 'e'=>$to);
}
return array("computed"=>$candidates, "missing"=>$needToCompute);
}它是一个函数,它返回两个数组,一个“计算”保存已经找到的计算片段,第二个“缺失”保存它们之间的空白,必须计算。
函数内部有0.1个阈值,这使得块长度小于搜索长度的10%,可以重写函数发送阈值作为参数,或者完全删除。
我假设结果将被存储,并在计算之后添加到缓存($oldResults)中,这可能是任何形式(例如,如Jeff所建议的数据库)。不要忘记将所有计算的块和整个查找长度添加到缓存中。
我很抱歉,但我找不到没有周期和假设的方法
工作演示:链接
https://stackoverflow.com/questions/37007123
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号