
巨型Json Parser
我有一个用Java制作的自定义解析器,我想将一个3,6 GB的Json导出到Sql数据库中。对于8MB的示例Json,导入很好。但是当我尝试解析整个3,6GB的JSON时,会出现一些内存问题,即java.lang.OutOfMemoryError
为此,我使用-Xmx5000m分配了5GB内存。我的笔记本电脑有很多内存。
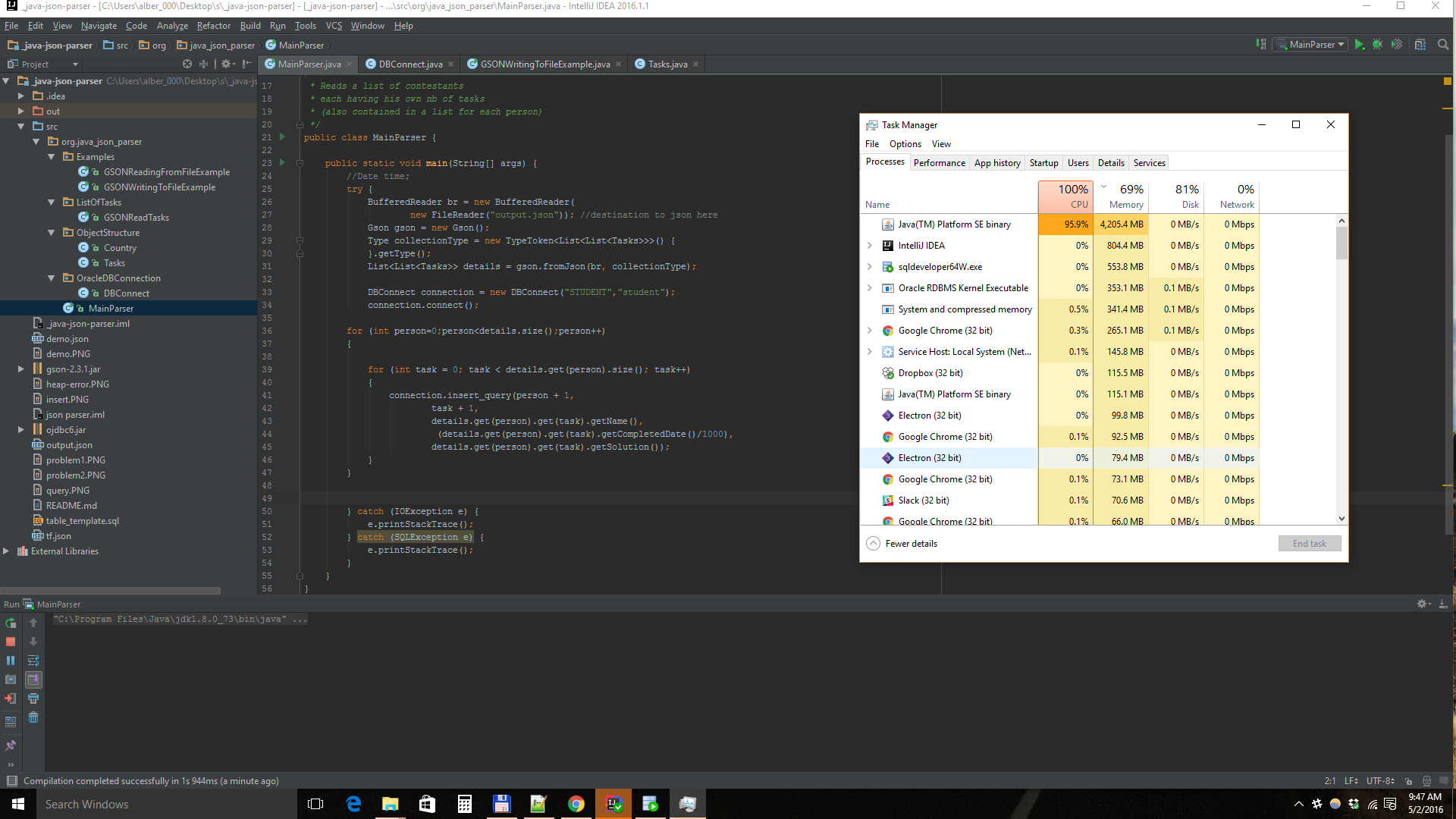
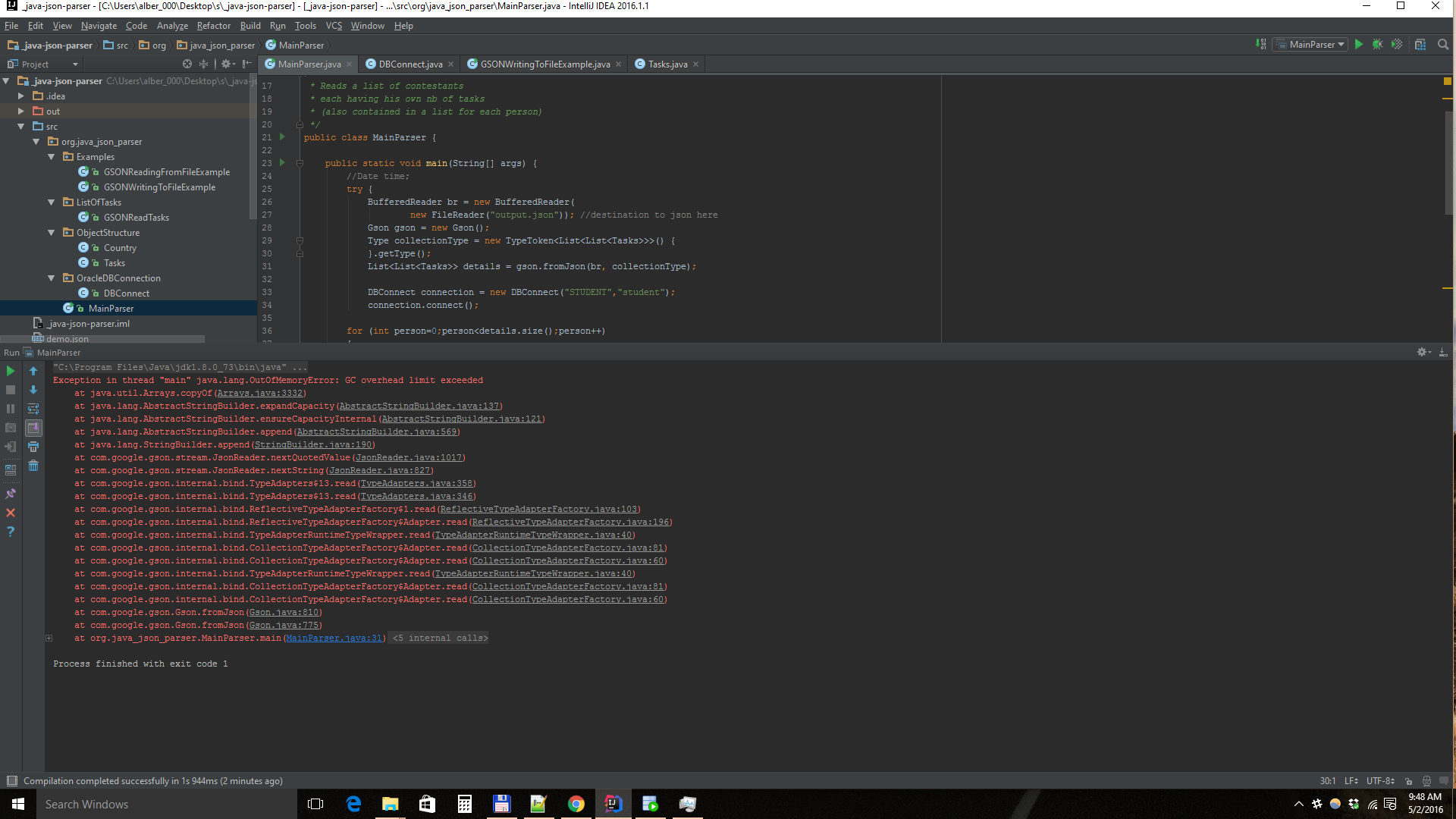
如你所见,我还有记忆。这个错误是因为CPU而发生的吗?
更新: Json代表免费代码营的数据:https://medium.freecodecamp.com/free-code-camp-christmas-special-giving-the-gift-of-data-6ecbf0313d62#.7mjj6abbg
数据如下:
[{“名称”:“Waypoint:向HTML元素问好”,“completedDate”:1445854025698,“解决方案”:“
Hello World
\n“}
正如我已经说过的,我已经尝试过用8MB的样本Json解析相同的数据,并且它起了作用。那么,代码真的是问题所在吗?
这是一些代码
enter code here
public class MainParser {
public static void main(String[] args) {
//Date time;
try {
BufferedReader br = new BufferedReader(
new FileReader("output.json")); //destination to json here
Gson gson = new Gson();
Type collectionType = new TypeToken<List<List<Tasks>>>() {
}.getType();
List<List<Tasks>> details = gson.fromJson(br, collectionType);
DBConnect connection = new DBConnect("STUDENT","student");
connection.connect();
for (int person=0;person<details.size();person++)
{
for (int task = 0; task < details.get(person).size(); task++)
{
connection.insert_query(person + 1,
task + 1,
details.get(person).get(task).getName(),
(details.get(person).get(task).getCompletedDate()/1000),
details.get(person).get(task).getSolution());
}
}
} catch (IOException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
}下面是insert_query方法:
enter code here
public void insert_query(int person_id, int task_id, String taskName, double date, String solution) throws SQLException {
Statement stmt = conn.createStatement();
try {
String query = "INSERT INTO FreeCodeCamp VALUES(?,?,?,?,?)";
PreparedStatement ps = conn.prepareStatement(query);
ps.setInt(1,person_id);
ps.setInt(2,task_id);
ps.setString(3,taskName);
ps.setDate(4,null);
ps.setString(5,solution);
/*stmt.executeUpdate("INSERT INTO FreeCodeCamp VALUES("
+ person_id + ","
+ task_id + ","
+ "'" + taskName + "',"
+ "TO_TIMESTAMP(unix_ts_to_date(" + date + "),'YYYY-MM-DD HH24:MI:SS'),"
+ "'" + solution + "')");
stmt.close();*/
ps.execute();
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}回答 3
Stack Overflow用户
发布于 2016-05-02 07:29:20
解析JSON (或其他任何东西)将不会占用与原始文件大小相同的内存。
表示对象的每个JSON字符串块都将成为一个对象,将内存添加到已经加载的JSON中。如果您使用某种流来解析它,您仍然会添加内存,但是会添加更少的内存(您不会将整个3.6GB文件保存在内存中)。
但是,对象比字符串所需的内存更多。如果您有一个数组(可能被解析为一个列表),则该列表的开销将大于该数组。将这一开销乘以JSON中的实例(非常多,在3.6GB文件中),最终占用的内存将远远超过3.6GB。
但是,如果要将其解析为流,并按其执行过程处理每条记录,则可以丢弃它。在这两种情况下,为了使用流,您将需要一个组件来解析JSON并让您处理每个解析的对象。如果你知道它的结构,那么你自己写一个就更容易了。
希望能帮上忙。
Stack Overflow用户
发布于 2016-05-02 07:41:18
您需要使用基于事件的/流JSON解析器。其思想是,解析器不是一次解析整个JSON文件并将其保存在内存中,而是在每个重要语法单元的开始和结束处发出“事件”。然后编写处理这些事件的代码,附加并组装信息,并(在您的情况下)将相应的记录插入数据库。
下面是一些开始阅读Oracle流JSON的地方:
- http://docs.oracle.com/javaee/7/api/javax/json/stream/JsonParser.html
- http://www.oracle.com/technetwork/articles/java/json-1973242.html
这里有一个指向GSON等效文档的链接:
Stack Overflow用户
发布于 2016-05-02 07:39:16
请参阅Gson的流式医生
当无法将整个模型加载到内存中时,将使用此方法。
https://stackoverflow.com/questions/36976737
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号