
NLTK树叶的绝对位置
我试图在给定的句子中找到名词短语的广度(开始索引,结束索引)。以下是提取名词短语的代码
sent=nltk.word_tokenize(a)
sent_pos=nltk.pos_tag(sent)
grammar = r"""
NBAR:
{<NN.*|JJ>*<NN.*>} # Nouns and Adjectives, terminated with Nouns
NP:
{<NBAR>}
{<NBAR><IN><NBAR>} # Above, connected with in/of/etc...
VP:
{<VBD><PP>?}
{<VBZ><PP>?}
{<VB><PP>?}
{<VBN><PP>?}
{<VBG><PP>?}
{<VBP><PP>?}
"""
cp = nltk.RegexpParser(grammar)
result = cp.parse(sent_pos)
nounPhrases = []
for subtree in result.subtrees(filter=lambda t: t.label() == 'NP'):
np = ''
for x in subtree.leaves():
np = np + ' ' + x[0]
nounPhrases.append(np.strip())A=“美国内战,也称为美国内战,是1861年至1865年在美国几个南方奴隶州宣布分离并组成美利坚合众国南部邦联后进行的内战。”
“美国内战”、“战争”、“各州”、“内战”、“内战”、“美国”、“几个南方”、“各州”、“分裂国家”、“南方邦联”、“美国”。
现在我需要找到名词短语的广度(短语的起始位置和结束位置)。例如,以上名词短语的跨度将是
(1,3),(9,9),(12,12),(16,17),(21,23),.
我对NLTK相当陌生,我研究过模块/nltk/tree.html。我尝试使用Tree.treepositions(),但无法使用这些索引提取绝对位置。任何帮助都将不胜感激。谢谢!
回答 3
Stack Overflow用户
发布于 2016-04-25 04:57:58
没有任何隐式函数返回https://github.com/nltk/nltk/issues/1214突出显示的字符串/令牌的偏移量。
但是您可以使用里贝斯评分从score.py#L123使用的ngram搜索程序。
>>> from nltk import word_tokenize
>>> from nltk.translate.ribes_score import position_of_ngram
>>> s = word_tokenize("The American Civil War, also known as the War between the States or simply the Civil War, was a civil war fought from 1861 to 1865 in the United States after several Southern slave states declared their secession and formed the Confederate States of America.")
>>> position_of_ngram(tuple('American Civil War'.split()), s)
1
>>> position_of_ngram(tuple('Confederate States of America'.split()), s)
43(它返回查询ngram的起始位置)
Stack Overflow用户
发布于 2019-02-17 16:55:28
这里是另一种方法,它用标记在树字符串中的绝对位置来增强它们。现在可以从任何子树的叶子中提取绝对位置。
def add_indices_to_terminals(treestring):
tree = ParentedTree.fromstring(treestring)
for idx, _ in enumerate(tree.leaves()):
tree_location = tree.leaf_treeposition(idx)
non_terminal = tree[tree_location[:-1]]
non_terminal[0] = non_terminal[0] + "_" + str(idx)
return str(tree)示例用例
>>> treestring = (S (NP (NNP John)) (VP (V runs)))
>>> add_indices_to_terminals(treestring)
(S (NP (NNP John_0)) (VP (V runs_1)))Stack Overflow用户
发布于 2020-09-27 10:16:54
使用以下代码实现了组成解析树的令牌偏移:
def get_tok_idx_of_tree(t, mapping_label_2_tok_idx, count_label, i):
if isinstance(t, str):
pass
else:
if count_label[0] == 0:
idx_start = 0
elif i == 0:
idx_start = mapping_label_2_tok_idx[list(mapping_label_2_tok_idx.keys())[-1]][0]
else:
idx_start = mapping_label_2_tok_idx[list(mapping_label_2_tok_idx.keys())[-1]][1] + 1
idx_end = idx_start + len(t.leaves()) - 1
mapping_label_2_tok_idx[t.label() + "_" + str(count_label[0])] = (idx_start, idx_end)
count_label[0] += 1
for i, child in enumerate(t):
get_tok_idx_of_tree(child, mapping_label_2_tok_idx, count_label, i)以下是组成树:
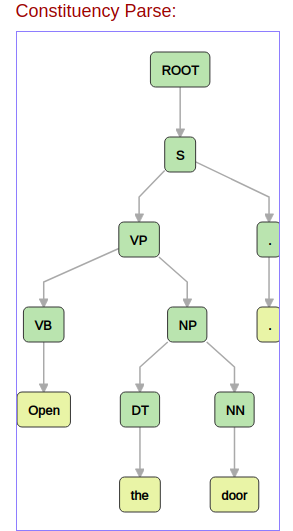
上述代码的输出:
{'ROOT_0': (0, 3), 'S_1': (0, 3), 'VP_2': (0, 2), 'VB_3': (0, 0), 'NP_4': (1, 2), 'DT_5': (1, 1), 'NN_6': (2, 2), '._7': (3, 3)}https://stackoverflow.com/questions/36831354
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号