
R:绘制子串的计数
R:绘制子串的计数
提问于 2016-04-21 16:52:14
我有一个数据框架,如下所示:
gender <- c("F", "M", "M", "M", "M")
entourage <- c("YC; AD; EL", "YC", "AD; YC", "AD", "EL")
data <- data.frame(gender, entourage)我想要画出子字符串"YC“、"AD”和"EL“在ggplot中出现的次数。考虑到性别是"M“,我也想画出"YC”的计数。
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-04-21 17:41:33
加载库:
library(tidyr)
library(dplyr)
library(ggplot2)我认为问题的症结在于将你的数据转换成tidy格式--或者至少是更易于管理的。创建一个整洁的data.frame
tidy.df <- data %>%
mutate(ent = strsplit(as.character(entourage), "; ")) %>%
unnest()
# head(tidy.df)
# gender entourage ent
# (fctr) (fctr) (chr)
# 1 F YC; AD; EL YC
# 2 F YC; AD; EL AD
# 3 F YC; AD; EL EL
# 4 M YC YC
# 5 M AD; YC AD
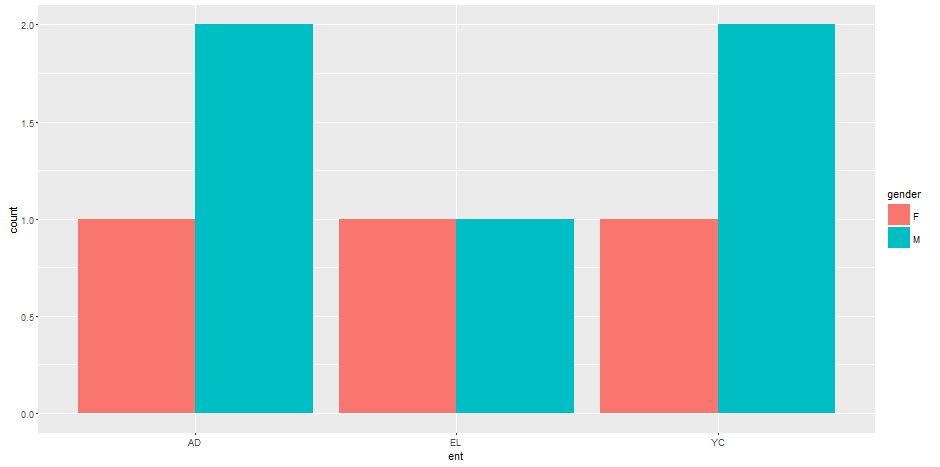
# 6 M AD; YC YC那么你就有了很多密谋的选择。看一下facet_wrap和facet_grid,或者geom_bar(position = "dodge")的例子。
ggplot(tidy.df, aes(x = ent, fill = gender)) +
geom_bar(position = "dodge")
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/36775986
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号