
cuFFT流的并发性
因此,我使用cuFFT与CUDA流特性相结合。我遇到的问题是,我似乎无法使cuFFT内核完全并发运行。以下是我从nvvp获得的结果。每个流都对128x128大小的128幅图像运行2D批处理FFT的内核。我设置了3个流运行3个独立的FFT批处理计划。
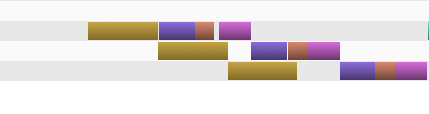
从图中可以看出,一些内存副本(黄色条)与一些内核计算(紫色、棕色和粉色条)并行。但是内核的运行完全不同步。正如您注意到的,每个内核都严格遵循彼此。下面是我用于将内存复制到设备和内核启动的代码。
for (unsigned int j = 0; j < NUM_IMAGES; j++ ) {
gpuErrchk( cudaMemcpyAsync( dev_pointers_in[j],
image_vector[j],
NX*NY*NZ*sizeof(SimPixelType),
cudaMemcpyHostToDevice,
streams_fft[j]) );
gpuErrchk( cudaMemcpyAsync( dev_pointers_out[j],
out,
NX*NY*NZ*sizeof(cufftDoubleComplex),
cudaMemcpyHostToDevice,
streams_fft[j] ) );
cufftExecD2Z( planr2c[j],
(SimPixelType*)dev_pointers_in[j],
(cufftDoubleComplex*)dev_pointers_out[j]);
}然后,我修改了代码,以便完成所有内存副本(同步),并立即将所有内核发送到流中,并得到以下分析结果:

然后我被证实内核不是以并行的方式运行的。
我看了一个链接,它详细解释了如何通过传递“-默认线程流”命令行参数或#在代码中包括或在代码中定义CUDA_API_PER_THREAD_DEFAULT_STREAM来设置使用完全并发性。这是CUDA 7中引入的一个特性。我在我的MacBook Pro Retina 15‘和GeForce GT750M (与上面的链接使用的机器相同)上运行了上面链接中的示例代码,并且能够获得并发内核运行。但我无法让我的cuFFT内核并行运行。
然后我找到了这个链接,有人说cuFFT内核将占用整个GPU,所以没有两个cuFFT内核并行运行。然后我被困住了。因为我没有找到任何正式的文档,说明CUFFT是否支持并发内核。这是真的吗?有办法解决这个问题吗?
回答 1
Stack Overflow用户
发布于 2016-04-16 01:59:02
我假设您在您展示的代码之前调用了cufftSetStream(),适合每个planr2c[j],因此每个计划都与一个单独的流相关联。我从你贴出的密码里看不见。如果您实际上希望袖圈内核与其他袖带内核重叠,则需要启动这些内核来分离流。因此,对图像0的cufft调用必须被启动到与对图像1的cufft调用不同的流中。
为了使任何两个数据自动化系统业务有重叠的可能性,必须将它们发射到不同的流中。
话虽如此,但并发内存复制了内核执行,而不是并发内核,这是我对合理大小的FFT所期望的。
一阶近似的128x128 FFT将旋转大约15,000个线程,因此,如果我的线程块每个线程大约有500个线程,那将是30个线程块,这将使GPU相当占去,为额外的内核留下很少的“空间”。(您实际上可以在分析器本身中发现内核的总块和线程。)你的GT750m 可能有2开普勒短消息有每SM最多16个区块,所以最大瞬时容量是32个街区。由于共享内存使用、寄存器使用或其他因素,可以减少特定内核的此容量数。
无论在哪个GPU上运行,其瞬时容量(每SM *SMs的最大块数)将决定内核重叠(并发)的可能性。如果使用单个内核启动就超过了该容量,那么这将“填充”GPU,从而在一段时间内防止内核并发。
从理论上讲,CUFFT内核应该可以同时运行。但是,就像任何内核并发场景( CUFFT或其他情况)一样,这些内核的资源利用率必须非常低才能真正看到并发性。通常,当资源使用率较低时,它意味着内核具有相对较少的线程/线程块。这些内核通常不需要很长时间来执行,因此更难看到并发性(因为启动延迟和其他延迟因素可能会阻碍)。查看并发内核的最简单方法是使内核具有异常低的资源需求以及异常长的运行时间。对于CUFFT内核或任何其他内核来说,这通常不是典型的场景。
复制和计算的重叠仍然是CUFFT流的一个有用的特性。而并发思想,没有一个理解机器容量和资源约束的基础,其本身是不合理的。例如,如果内核并发是可以任意实现的(“我应该能够使任意2个内核并发运行”),而不考虑容量或资源的具体情况,那么在两个内核同时运行之后,下一个逻辑步骤将是并发运行到4、8、16个内核。但现实是,机器不能同时处理那么多的工作。一旦您在单个内核启动中公开了足够的并行性(松散地翻译为“足够多的线程”),通过额外的内核启动公开额外的工作并行通常不能使机器运行得更快,或者处理的更快。
https://stackoverflow.com/questions/36658324
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号