
Spark中Pregel的许多跳过的阶段
Spark中Pregel的许多跳过的阶段
提问于 2016-04-12 13:34:54
我试图在connected components上运行logNormalGraph。
val graph: Graph[Long, Int] = GraphGenerators.
logNormalGraph(context.spark, numEParts = 10, numVertices = 1000000,
mu = 0.01, sigma = 0.01)
val minGraph = graph.connectedComponents()在星星之火用户界面中,我可以看到每一个下一个工作都会有越来越多的跳过的阶段。
1 - 4/4 (12 skipped)
2 - 4/4 (23 skipped)
...
50 - 4/4 (4079 skipped)为什么我在Pregel上运行的时候有这么多跳过的阶段,为什么这个数字增长如此之快(非线性)?
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-04-12 19:06:13
循序渐进。connectedComponents函数已实现使用预凝胶API。迭代地忽略特定于算法的细节:
- 缓存输出
mapReduceTriplets在messages上
首先让我们创建虚拟sendMsg
import org.apache.spark.graphx._
def sendMsg(edge: EdgeTriplet[VertexId, Int]):
Iterator[(VertexId, VertexId)] = {
Iterator((edge.dstId, edge.srcAttr))
}vprog
val vprog = (id: Long, attr: Long, msg: Long) => math.min(attr, msg)和megeMsg
val mergeMsg = (a: Long, b: Long) => math.min(a, b)接下来,我们可以使用初始化示例图:
import org.apache.spark.graphx.util.GraphGenerators
val graph = GraphGenerators.logNormalGraph(
sc, numEParts = 10, numVertices = 100, mu = 0.01, sigma = 0.01)
.mapVertices { case (vid, _) => vid }
val g0 = graph
.mapVertices((vid, vdata) => vprog(vid, vdata, Long.MaxValue))
.cache()和消息
val messages0 = g0.mapReduceTriplets(sendMsg, mergeMsg).cache()由于GraphXUtils是私有的,所以我们必须直接使用Graph方法。
当您查看由
messages0.count您已经看到了一些跳过的阶段:
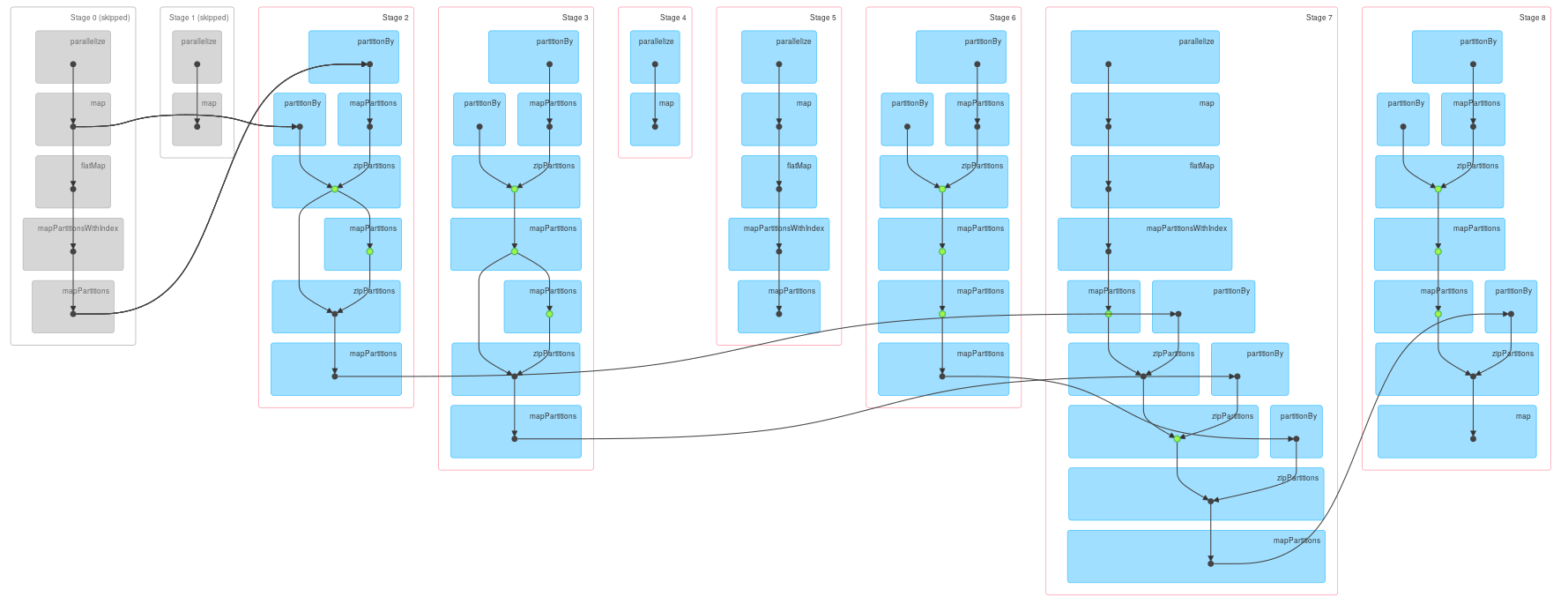
在执行第一个迭代之后
val g1 = g0.joinVertices(messages0)(vprog).cache()
val messages1 = g1.mapReduceTriplets(sendMsg, mergeMsg).cache()
messages1.count图形的外观大致如下:

如果我们继续:
val g2 = g1.joinVertices(messages1)(vprog).cache()
val messages2 = g2.mapReduceTriplets(sendMsg, mergeMsg).cache()
messages2.count我们跟踪DAG:

所以这里发生了什么:
- 我们执行迭代算法,对同一数据进行两次依赖,一次用于连接,一次用于消息聚合。这导致
g在每次迭代中所依赖的阶段越来越多。 - 由于数据是密集缓存的(正如您在代码中所看到的那样,显式地通过持久化混洗文件来显式地缓存数据)和校验点(这里我可能错了,但检查点通常被标记为绿色点),因此每个阶段只能计算一次,即使多个下游阶段依赖于此。
- 在初始化数据(
g0、messages0)之后,只从零开始计算最新的阶段。 - 如果您仔细观察
DAG,您会发现存在相当复杂的依赖关系,这应该可以解释DAG相对缓慢的增长和跳过的阶段数之间的差异。
第一个属性解释了越来越多的阶段,第二个属性解释了阶段被跳过的事实。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/36574946
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号