
用qdap对评论的情感分析比较慢
Am使用qdap包来确定特定应用程序的每个评论评论的情绪。我从CSV文件中读取评论并将其传递给qdap的极性函数。一切正常,我得到所有评论的极性,但问题是,计算所有句子的极性需要7-8秒( CSV文件中的句子总数为779)。我正在粘贴下面的代码。
temp_csv <- filePath()
attach(temp_csv)
text_data <- temp_csv[,c('Content')]
print(Sys.time())
polterms <- list(neg=c('wtf'))
POLKEY <- sentiment_frame(positives=c(positive.words),negatives=c(polterms[[1]],negative.words))
polarity <- polarity(sentences, polarity.frame = POLKEY)
print(Sys.time())所需时间如下:
1 "2016-04-12 16:43:01 IST“
1 "2016-04-12 16:43:09 IST“
如果我做错了什么,谁能告诉我吗?我怎样才能提高成绩呢?
回答 1
Stack Overflow用户
发布于 2016-04-12 14:38:55
我是qdap的作者。polarity函数是为小得多的数据集设计的。随着我角色的转变,我开始使用更大的数据集。我需要快速和准确(这两件事是对立的),并已经开发了一个脱离包感伤。优化后的算法比qdap的极性更快、更准确。
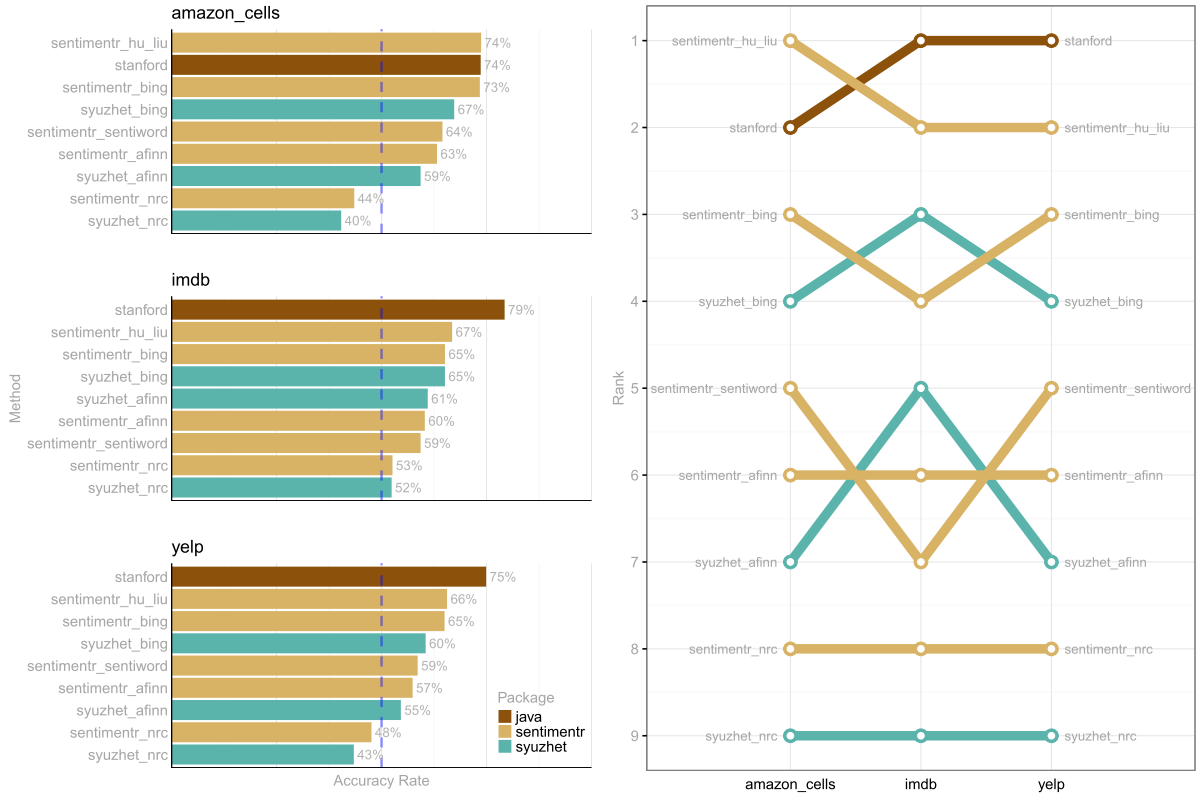
现在,您已经有5个基于字典的(或基于训练算法的)接近情绪检测。每一个都有它的缺点(-)和优点(+),在某些情况下是有用的。
- qdap +on CRAN;-slow
- 苏泽特 +对CRAN;+快速;+伟大的绘图;-less精确的非文学用途
- 感伤 +快速;+高精度;仅限-GitHub
- 斯坦森(斯坦福港) +最精确;-slower
- tm.plugin.sentiment -archived on CRAN;-I不容易让它工作
我在下面的代码中显示了前面4种选择的样本数据的时间测试。
安装软件包并执行计时功能
我使用pacman是因为它允许读取器只运行代码;尽管您可以用install.packages & library调用来替换。
if (!require("pacman")) install.packages("pacman")
pacman::p_load(qdap, syuzhet, dplyr)
pacman::p_load_current_gh(c("trinker/stansent", "trinker/sentimentr"))
pres_debates2012 #nrow = 2912
tic <- function (pos = 1, envir = as.environment(pos)){
assign(".tic", Sys.time(), pos = pos, envir = envir)
Sys.time()
}
toc <- function (pos = 1, envir = as.environment(pos)) {
difftime(Sys.time(), get(".tic", , pos = pos, envir = envir))
}
id <- 1:2912时差
## qdap
tic()
qdap_sent <- pres_debates2012 %>%
with(qdap::polarity(dialogue, id))
toc() # Time difference of 18.14443 secs
## sentimentr
tic()
sentimentr_sent <- pres_debates2012 %>%
with(sentiment(dialogue, id))
toc() # Time difference of 1.705685 secs
## syuzhet
tic()
syuzhet_sent <- pres_debates2012 %>%
with(get_sentiment(dialogue, method="bing"))
toc() # Time difference of 1.183647 secs
## stanford
tic()
stanford_sent <- pres_debates2012 %>%
with(sentiment_stanford(dialogue))
toc() # Time difference of 6.724482 mins要了解更多关于时间和准确性的信息,请访问我的感伤型README.md,如果它是有用的,请星号回购。下面的内容捕获了自述文件中的一个测试:
https://stackoverflow.com/questions/36572677
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号