
读文本编码问题
我读过一个特定的纯文本文件(csv),我对xA0有一个问题。
Visual Studio 2015:
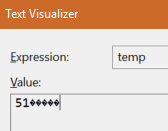
Notepad++:(将char编码设置为utf-8时)
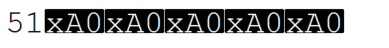
所以似乎是这个不破空间,所以我尝试了这
temp = temp.Replace("\xA0", string.Empty);但是它不起作用,给了我类似于第一张截图的黑色方块。我也改变了
System.IO.StreamReader sr = new System.IO.StreamReader(csvFile.FileContent);使用特定的utf-8编码:
System.IO.StreamReader sr = new System.IO.StreamReader(csvFile.FileContent, System.Text.Encoding.UTF8);两人都给出了同样的结果。我真的不喜欢char编码,我需要一些帮助和解释我的错误。
编辑添加了notepad++十六进制视图:(确认它是不中断的字符)

edit2将流读取器构造函数值更改为:
System.IO.StreamReader sr = new System.IO.StreamReader(csvFile.FileContent, true);结果是要读取文件的utf-8编码。我试图将latin1转换为utf-8,但这给了我??? https://stackoverflow.com/a/13999801/169714。
Encoding.UTF8.GetString(Encoding.GetEncoding("iso-8859-1").GetBytes(temp))回答 2
Stack Overflow用户
发布于 2016-04-12 09:38:04
尝试将结果放入字符串,读取数据并打印出结果。
就像这样:
string[] data = File.ReadAllLines(yourSavePath);
File.WriteAllLines(yourSavePath, data);如果我是对的,它应该修复它,这是一个缺少字符的问题。
Stack Overflow用户
发布于 2016-04-12 10:12:21
0xA0是Latin1 ( iso-8859-1 )中的不间断空间.您可以通过将Encoding.GetEncoding("iso-8859-1")作为编码传递来读取它:
var latin1= Encoding.GetEncoding("iso-8859-1");
var sr = new System.IO.StreamReader(csvFile.FileContent, latin1);例如,对于输入数组:
byte[] values={0x53,0x34,0x35,0x3b,0x35,0x31,0xa0,0xa0,0xa0,0xa0,0xa0};UTF8返回
var s1=Encoding.UTF8.GetString(values);
Console.WriteLine(s1);S45;51�����
而Latin1则返回有效的字符串
var s2=latin1.GetString(values);
Console.WriteLine(s2);S45;51
.NET对字符串使用Unicode,默认情况下使用UTF8读取文本文件。例如,流读物构造函数默认为UTF8:
public StreamReader(Stream stream)
: this(stream, true) {
}
public StreamReader(Stream stream, bool detectEncodingFromByteOrderMarks)
: this(stream, Encoding.UTF8, detectEncodingFromByteOrderMarks, DefaultBufferSize, false) {
}若要使用系统区域设置,必须显式传递Encoding.Default编码。
var sr = new System.IO.StreamReader(csvFile.FileContent, Encoding.Default);许多西欧和英语国家确实使用了这种编码方式,因此系统的区域设置可以预计为Latin1。然而,在进口工作中,这是一个冒险的假设。
https://stackoverflow.com/questions/36569218
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号