
Apache多个消费者实例
Apache多个消费者实例
提问于 2016-04-01 06:45:13
我有一个消费者应该从一个主题中读取信息。这个使用者实际上读取消息并将它们写入时间序列数据库。我们有多个时间序列数据库实例,作为集群在多台物理机器上运行。
我们的计划是在运行时间序列服务的所有机器上部署使用者。因此,如果我有5个节点运行时间序列服务,我将在每个节点上安装一个使用者实例。所有这些使用者实例都属于同一个使用者组。因此,在图片中,设置如下:
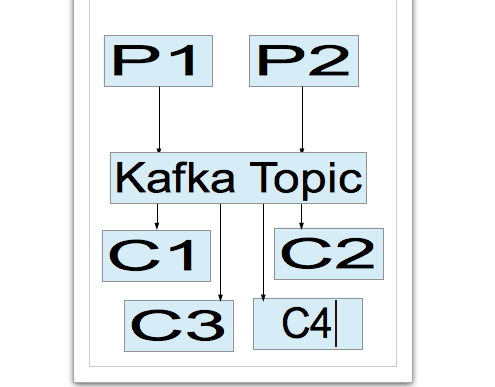
如您所见,生产者P1和P2将写入两个分区,即kafka主题的分区1和分区2。然后,我有4个时间序列服务实例,其中每个实例运行一个使用者。我应该如何正确地使用我的使用者来读取,以避免在我的时间序列数据库中出现重复的消息?
编辑:在阅读了卡夫卡的文档之后,我偶然发现了以下两种说法:
If all the consumer instances have the same consumer group, then this works just like a traditional queue balancing load over the consumers.
If all the consumer instances have different consumer groups, then this works like publish-subscribe and all messages are broadcast to all consumers.所以,在我上面的例子中,它的行为就像一个队列?我的理解正确吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-04-01 07:55:04
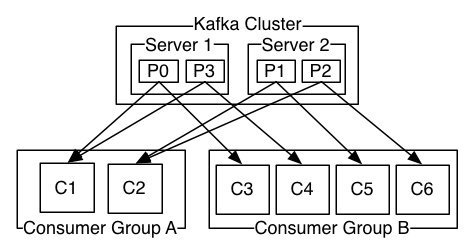
如果所有消费者都属于一个组(拥有相同的groupId),那么kafka主题将作为一个队列来处理。
重要的是:没有理由有更多的消费者超过分区,因为消费者(开箱即用的卡夫卡消费者)是按分区缩放的。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/36349705
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号