
字符集问题UTF-8
我有一个文档,其中的单词“word”包含了如下所示的撇号。
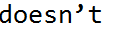
当我试图通过python程序处理这个问题时,它会将单词显示为“mentioned”,并按照下面提到的错误退出。
UnicodeDecodeError: 'utf8' codec can't decode byte 0x92 in position 70: invalid start byte我在记事本中打开了文档,并将编码从ANSI更改为UTF-8 (在网上找到),现在它工作正常。
但是,有人能说清楚,所有这些都是关于什么的,以及我如何用我的笔记本键盘输入那种撇号。
回答 1
Stack Overflow用户
发布于 2016-03-16 09:47:06
著名的Word女士将引号转换为“智能引号”,这样它们就能正确地围绕单词或指向正确的方向作为撇号。
你并没有完全忠实于你的复制粘贴,所以很难确定我们是在谈论同样的事情。
例如,以下是与普通ascii相比的智能引号:
不与不
或
“你好”与“你好”
注意左边的智能引号是怎样的居中点。在截图中,’将被映射到Unicode点U+2019 (‘右单引号’)。使用Windows键组合并键入Unicode值,您很难手动键入智能引号。
然后,您可能已经保存了此文本,如Windows1252(西欧)编码(又名ANSI),其中分配了字节0x92。然后,您将其加载到Python中,但传递了不正确的UTF-8编码。那时你就看到了例外。
将来处理这个问题的方法是在Python中打开文件时指定正确的编码。例如。
with io.open("myfile.txt", 'r', encoding="windows-1252") as my_file:
my_data = my_file.read()https://stackoverflow.com/questions/36027875
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号