
解释NVIDIA视觉分析器输出
我最近已经开始玩NVIDIA视觉探查器(CUDA 7.5)来计时我的应用。
然而,我似乎并不完全理解我得到的输出的含义。我不知道如何对不同的分析器输出采取行动。
作为一个例子:在一个for循环中调用单个内核~360次的数据自动化代码。每次,内核计算大约1000个3D纹理存储器读取的512^2次数。每个512^2单元都分配一个线程。需要一些算法才能知道在纹理存储器中读取的位置。纹理存储器读取不需要插值,总是在精确的数据索引中。之所以选择3D纹理存储器,是因为记忆将是相对随机的,因此内存合并是不被期望的。我找不到这方面的参考资料,但肯定是在某个地方读到的。
描述很简短,但我希望它能给出内核所做操作的一个小的概述(发布整个内核可能太多了,但如果需要的话,我可以)。
从现在开始,我将描述我对分析器的解释。
在分析时,如果运行Examine GPU usage,就会得到(单击以放大):
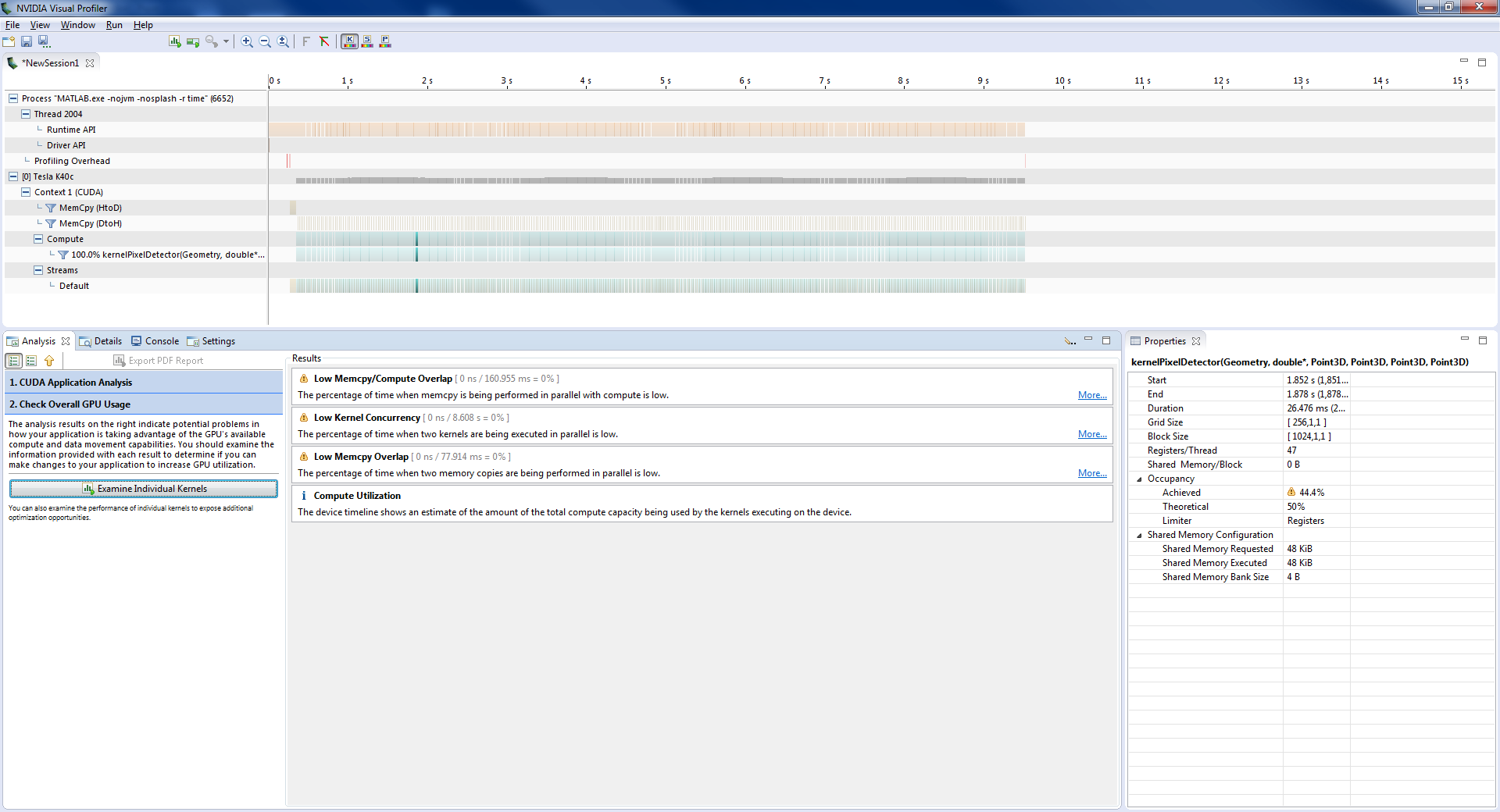
从这里我看到了几件事:
- 低拷贝/计算重叠 0%。这是意料之中的,因为我运行了一个大内核,等待它完成,然后再复制。不应该有重叠。
- 低内核并发性 0%。我刚得到了一个内核,这是预料中的。
- 低拷贝重叠 0%。同样的事情。我只在乞讨中复制一次,在每个内核之后只复制一次。这是意料之中的。
从内核执行“条形码”中,我可以看到顶部和右边:
- 大部分时间是运行内核。内存开销很小。
- 所有的内核都有相同的时间(很好)
- 最大的旗子是占用率,总是低于45%,是注册的限制者。然而,优化入住率似乎并不总是优先考虑.
我按照我的分析方式运行Perform Kernel Analysis,得到:
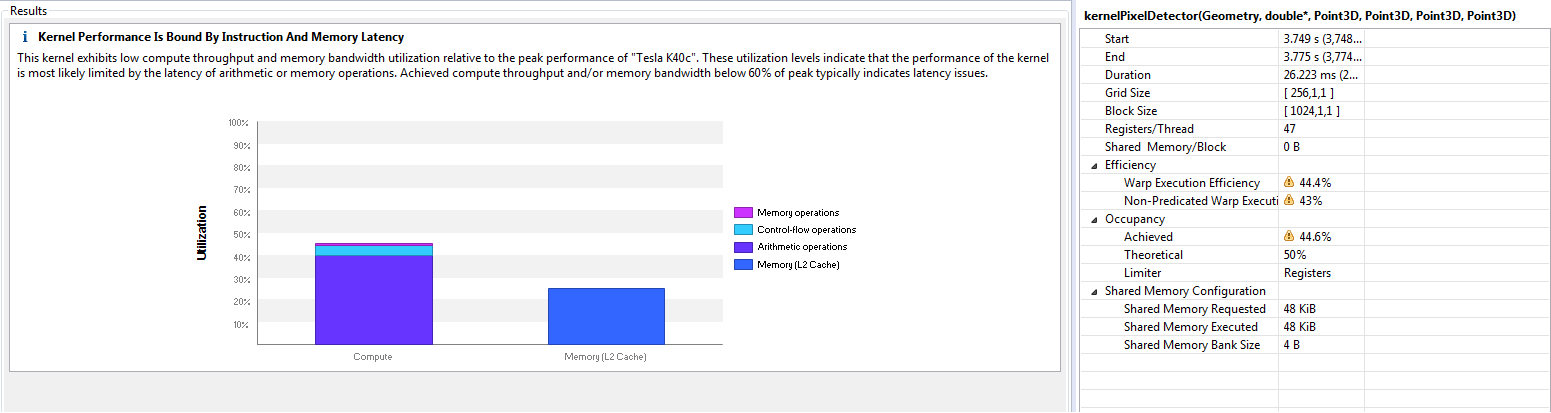
我能在这里看到
- 内核中的计算和内存利用率很低。分析人员认为,低于60%是没有好处的。
- 大部分时间是在计算和L2缓存读取。
还有别的吗?
我继续使用Perform Latency Analysis,因为分析器显示最大的瓶颈在那里。
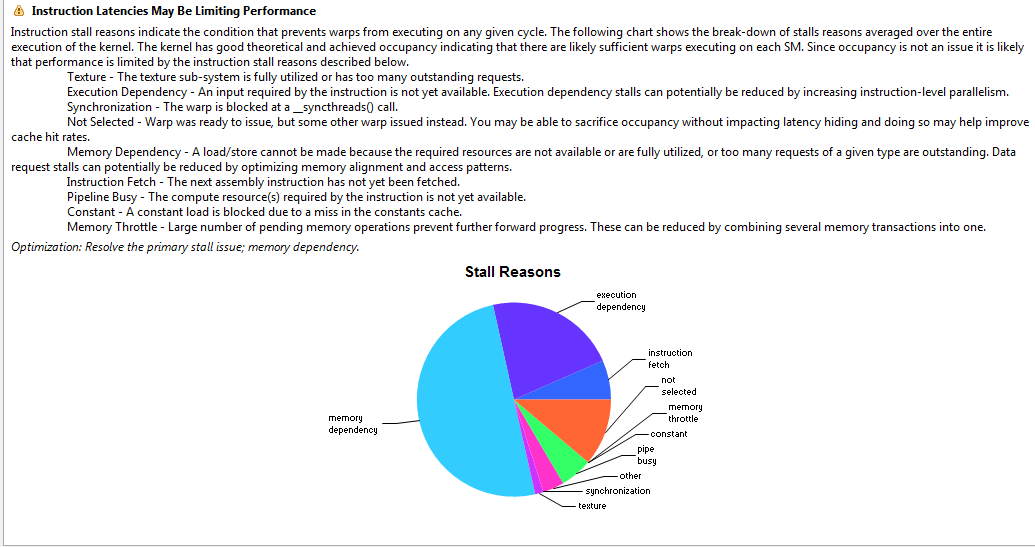
最大的三个原因似乎是
- 内存依赖项。纹理记忆太多了吗?但我需要这么多备忘录。
- 执行依赖项。“可以通过增加指令级并行度来减少”。这是否意味着我应该尝试将
a=a+1;a=a*a;b=b+1;b=b*b;改为a=a+1;b=b+1;a=a*a;b=b*b;? - 指令获取(?)
问题:
- 是否还有更多的额外测试可以让我更好地理解内核的执行时间限制?
- 是否有一种方法可以在内核内部的指令级别上进行概要分析?
- 是否有比我所得到的更多的结论可以通过分析得到?
- 如果我要开始优化内核,我会从哪里开始?
回答 1
Stack Overflow用户
发布于 2016-03-10 23:43:39
是否还有更多的额外测试可以让我更好地理解内核的执行时间限制?
当然了!如果您注意“属性”窗口。您的屏幕截图告诉您,您的内核1.受注册使用的限制(请在“kernel”分析中查看它),2. 2.Warp效率很低(小于100%意味着线程分叉)(请在“Divergent Execution”中检查它)。
是否有一种方法可以在内核内部的指令级别上进行概要分析?
是的,您有两种类型的分析:
- “内核配置文件-指令执行”
- “内核配置文件- PC采样”(仅在Maxwell中)
是否有比我所得到的更多的结论可以通过分析得到?
您应该检查内核是否有一些线程差异。此外,您应该检查共享/全局内存访问模式是否存在问题。
如果我要开始优化内核,我会从哪里开始?
我发现内核延迟窗口是最有用的窗口,但我认为它取决于您正在分析的内核类型。
https://stackoverflow.com/questions/35893114
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号