
是否有任何由Hotspot JIT编译器完成的指令重新排序可以复制?
如我们所知,一些JIT允许为对象初始化重新排序,例如,
someRef = new SomeObject();可以分解为以下步骤:
objRef = allocate space for SomeObject; //step1
call constructor of SomeObject; //step2
someRef = objRef; //step3JIT编译器可以按以下方式重新排序:
objRef = allocate space for SomeObject; //step1
someRef = objRef; //step3
call constructor of SomeObject; //step2也就是说,step2和step3可以由JIT编译器重新排序。尽管这在理论上是有效的重新排序,但我无法在x86平台下用Hotspot(jdk1.7)再现它。
那么,是否有任何指令重新排序由Hotspot JIT comipler完成,可以复制?
Update:我使用以下命令在机器(Linux x86_64、JDK 1.8.0_40、i5-3210M )上执行了测试:
java -XX:-UseCompressedOops -XX:+UnlockDiagnosticVMOptions -XX:CompileCommand="print org.openjdk.jcstress.tests.unsafe.UnsafePublication::publish" -XX:CompileCommand="inline, org.openjdk.jcstress.tests.unsafe.UnsafePublication::publish" -XX:PrintAssemblyOptions=intel -jar tests-custom/target/jcstress.jar -f -1 -t .*UnsafePublication.* -v > log.txt 我可以看到报告的工具是这样的:
可接受的对象被发布,至少有一个字段是可见的。
这意味着一个观察者线程看到了一个未初始化的MyObject实例。
但是,我没有看到像@Ivan那样生成的程序集代码:
0x00007f71d4a15e34: mov r11d,DWORD PTR [rbp+0x10] ;getfield x
0x00007f71d4a15e38: mov DWORD PTR [rax+0x10],r11d ;putfield x00
0x00007f71d4a15e3c: mov DWORD PTR [rax+0x14],r11d ;putfield x01
0x00007f71d4a15e40: mov DWORD PTR [rax+0x18],r11d ;putfield x02
0x00007f71d4a15e44: mov DWORD PTR [rax+0x1c],r11d ;putfield x03
0x00007f71d4a15e48: mov QWORD PTR [rbp+0x18],rax ;putfield o这里似乎没有编译器重新排序。
Update2:“伊万纠正了我。我使用了错误的JIT命令来捕获修复此错误的程序集code.After,我可以在程序集代码下面获取:
0x00007f76012b18d5: mov DWORD PTR [rax+0x10],ebp ;*putfield x00
0x00007f76012b18d8: mov QWORD PTR [r8+0x18],rax ;*putfield o
; - org.openjdk.jcstress.tests.unsafe.generated.UnsafePublication_jcstress$Runner_publish::call@94 (line 156)
0x00007f76012b18dc: mov DWORD PTR [rax+0x1c],ebp ;*putfield x03显然,编译器进行了重新排序,这导致了不安全的发布。
回答 1
Stack Overflow用户
发布于 2016-03-09 22:01:02
您可以复制任何编译器重新排序。正确的问题是--使用哪种工具来解决这个问题。为了查看编译器的重新排序,您必须使用JITWatch(因为它使用HotSpot的组装日志输出)或使用LinuxPerfAsmProfiler的JMH来跟踪到程序集级别。
让我们考虑基于JMH的以下基准:
public class ReorderingBench {
public int[] array = new int[] {1 , -1, 1, -1};
public int sum = 0;
@Benchmark
public void reorderGlobal() {
int[] a = array;
sum += a[1];
sum += a[0];
sum += a[3];
sum += a[2];
}
@Benchmark
public int reorderLocal() {
int[] a = array;
int sum = 0;
sum += a[1];
sum += a[0];
sum += a[3];
sum += a[2];
return sum;
}
}请注意数组访问是无序的。在上,具有全局变量sum汇编程序输出的方法的机器是:
mov 0xc(%rcx),%r8d ;*getfield sum
...
add 0x14(%r12,%r10,8),%r8d ;add a[1]
add 0x10(%r12,%r10,8),%r8d ;add a[0]
add 0x1c(%r12,%r10,8),%r8d ;add a[3]
add 0x18(%r12,%r10,8),%r8d ;add a[2]但是,对于具有局部变量sum访问模式的方法,更改了:
mov 0x10(%r12,%r10,8),%edx ;add a[0] <-- 0(0x10) first
add 0x14(%r12,%r10,8),%edx ;add a[1] <-- 1(0x14) second
add 0x1c(%r12,%r10,8),%edx ;add a[3]
add 0x18(%r12,%r10,8),%edx ;add a[2]您可以使用c1编译器优化RangeCheckElimination。
更新:
从用户的角度来看,只看到编译器重新排序是非常困难的,因为您必须运行大量的示例才能捕捉到这种动态行为。另外,区分编译器和硬件问题也很重要,例如,弱排序的硬件(如POWER )可以改变行为。让我们从正确的工具开始:强应力 --一个实验性的工具和一组测试,以帮助研究JVM、类库和硬件中的并发支持的正确性。这里是一个复制器,指令调度程序可能决定发出几个字段存储,然后发布引用,然后发出其余的字段存储(还可以阅读有关安全发布和指令调度这里的信息)。在某些情况下,在我的机器上使用Linux x86_64,JDK 1.8.0_60,i5-4300M编译器生成以下代码:
mov %edx,0x10(%rax) ;*putfield x00
mov %edx,0x14(%rax) ;*putfield x01
mov %edx,0x18(%rax) ;*putfield x02
mov %edx,0x1c(%rax) ;*putfield x03
...
movb $0x0,0x0(%r13,%rdx,1) ;*putfield o但有时:
mov %ebp,0x10(%rax) ;*putfield x00
...
mov %rax,0x18(%r10) ;*putfield o <--- publish here
mov %ebp,0x1c(%rax) ;*putfield x03
mov %ebp,0x18(%rax) ;*putfield x02
mov %ebp,0x14(%rax) ;*putfield x01更新2:
关于绩效福利的问题。在我们的例子中,这种优化(重新排序)并没有带来有意义的性能好处--这只是编译器实现的一个副作用。HotSpot使用sea of nodes图对数据和控制流进行建模(您可以阅读基于图形的中间表示这里)。下图显示了我们示例的IR图(-XX:+PrintIdeal -XX:PrintIdealGraphLevel=1 -XX:PrintIdealGraphFile=graph.xml options + 理想图形可视化器):
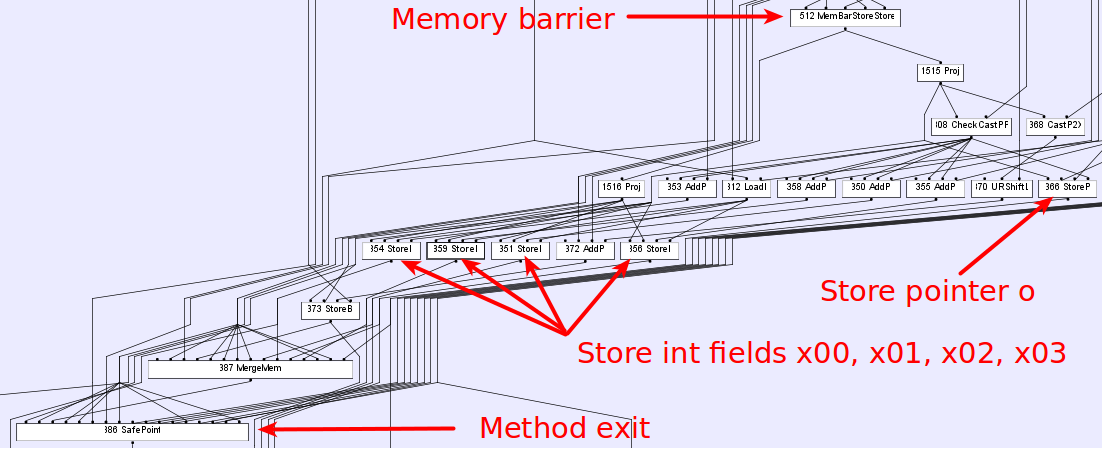
其中对节点的输入是对节点操作的输入。每个节点根据其输入和操作定义一个值,该值在所有输出边上都可用。很明显,编译器没有看到指针和整数存储节点之间的任何区别,因此唯一限制它的是内存屏障。因此,为了降低寄存器压力,目标代码大小或其他编译器决定按照这个strange(from用户的观点在基本块内调度指令)。您可以使用以下选项(在快速调试构建中可用)来处理Hotspot中的指令调度:-XX:+StressLCM和-XX:+StressGCM。
https://stackoverflow.com/questions/35883354
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号