
梯度下降与随机梯度下降算法
我尝试在MNIST手写体数字数据集(包括60K训练样本)上训练一个FeedForward神经网络。
我每次都在上迭代所有的训练样本(),在每个时期对每个这样的样本执行。运行时当然太长了。
- 是我运行的名为梯度下降的算法。
我读到,对于大型数据集,使用随机梯度下降可以显着地改善运行时。
- 为了使用随机梯度下降,我应该做什么?我是否应该随机选择训练样本,对每个随机抽取的样本执行Backpropagation,而不是我目前使用的历次?
回答 2
Stack Overflow用户
发布于 2016-03-01 09:23:13
您描述的新场景(对每个随机选择的样本执行反向传播)是随机梯度下降的一个常见的“味道”,如下所述:https://www.quora.com/Whats-the-difference-between-gradient-descent-and-stochastic-gradient-descent
根据本文档,最常见的三种口味是(您的口味是C):
a)
randomly shuffle samples in the training set
for one or more epochs, or until approx. cost minimum is reached:
for training sample i:
compute gradients and perform weight updatesb)
for one or more epochs, or until approx. cost minimum is reached:
randomly shuffle samples in the training set
for training sample i:
compute gradients and perform weight updatesc)
for iterations t, or until approx. cost minimum is reached:
draw random sample from the training set
compute gradients and perform weight updatesStack Overflow用户
发布于 2016-03-01 09:49:11
我试着给你一些直觉.
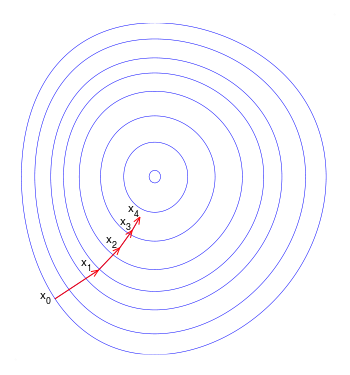
最初,更新是在您(正确)称为(批处理)渐变下降中进行的。这保证了权重中的每一个更新都是在“正确”的方向上进行的(如图所示)。( 1):使成本函数最小化的函数。
{kind=link}
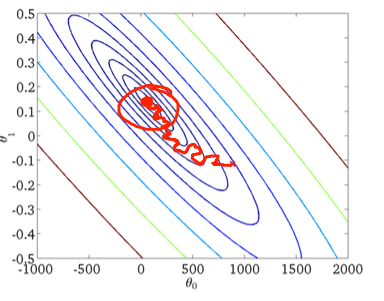
随着数据集大小的增加和每一步计算的复杂性,随机梯度下降在这些情况下成为首选。在这里,对权重的更新是在处理每个样本时完成的,因此,随后的计算已经使用了“改进的”权重。尽管如此,这个原因导致它在最小化错误函数时产生了一些错误的方向(如图所示)。2)。
{kind=link}
因此,在许多情况下,最好使用最小批处理梯度下降,将两者结合起来:每次更新权重都使用一小批数据。这样,与随机更新相比,更新的方向得到了一定的纠正,但更新比(原始的)梯度下降的情况更有规律。
根据请求更新,下面是二进制分类中批处理梯度下降的伪代码:
error = 0
for sample in data:
prediction = neural_network.predict(sample)
sample_error = evaluate_error(prediction, sample["label"]) # may be as simple as
# module(prediction - sample["label"])
error += sample_error
neural_network.backpropagate_and_update(error)(在多类标记的情况下,error表示每个标签的错误数组。)
此代码在给定次数的迭代中运行,或者在错误超过阈值时运行。对于随机梯度下降,在For循环中调用neural_network.backpropagate_and_update(),并以样本错误作为参数。
https://stackoverflow.com/questions/35711315
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号