
策划多个范畴
我有如下数据,每个实验都会导致一篇作文的出现,而每一篇作文都属于一个或多个类别。我想画出每一篇作文的出现次数:
DF <- read.table(text = " Comp Category
Comp1 1
Comp2 1
Comp3 4,2
Comp4 1,3
Comp1 1,2
Comp3 3 ", header = TRUE)
barplot(table(DF$Comp))所以这对我来说是完美的。
在此之后,构图属于一个或多个类别。在类别之间有逗号分隔,我想用X来标出复音,用Y表示复数的nb,对每一栏分别画出每个类别的%。
我的想法是复制有逗号的行,因此,为了避免它N+1逗号的数量。
DF = table(DF$Category,DF$Comp)
cats <- strsplit(rownames(DF), ",", fixed = TRUE)
DF <- DF[rep(seq_len(nrow(DF)), sapply(cats, length)),]
DF <- as.data.frame(unclass(DF))
DF$cat <- unlist(cats)
DF <- aggregate(. ~ cat, DF, FUN = sum)它将给我举个例子:对于Comp1
1 2 3 4
Comp1 2 1 0 0但是,如果应用这种方法,类别(3)的总数将不与组合总数(comp1=2)相对应。
在这种情况下如何进行?解决方案是以逗号+1的nb为分隔符吗?如果是,如何在我的代码中这样做,还有最简单的方法吗?
非常感谢!
回答 1
Stack Overflow用户
发布于 2016-03-01 10:05:48
生成您的情节需要两个步骤,正如您已经注意到的。首先,需要准备数据,然后才能创建情节。
准备数据
你已经展示了你的努力,把数据以一种适当的形式,但让我提出另一种方式。
首先,我必须确保数据帧的Category列是一个字符,而不是一个因素。我还存储数据框架中出现的所有类别的向量:
DF$Category <- as.character(DF$Category)
cats <- unique(unlist(strsplit(DF$Category, ",")))然后我需要总结一下数据。为此,我需要一个函数,为Comp中的每个值提供按比例缩放的每个类别的百分比,使值之和给出原始数据中带有该Comp的行数。
下面的函数以另一个数据帧的形式返回整个数据帧的此信息(输出需要是一个数据框架,因为我希望稍后在do()中使用该函数)。
cat_perc <- function(cats, vec) {
# percentages
nums <- sapply(cats, function(cat) sum(grepl(cat, vec)))
perc <- nums/sum(nums)
final <- perc * length(vec)
df <- as.data.frame(as.list(final))
names(df) <- cats
return(df)
}在完整的数据框架上运行该函数将提供:
cat_perc(cats, DF$Category)
## 1 4 2 3
## 1 2.666667 0.6666667 1.333333 1.333333值之和为6,这实际上是原始数据帧中的行总数。
现在,我们希望对Comp的每个值运行该函数,这可以使用dplyr包来完成:
library(dplyr)
plot_data <-
group_by(DF, Comp) %>%
do(cat_perc(cats, .$Category))
plot_data
## plot_data
## Source: local data frame [4 x 5]
## Groups: Comp [4]
##
## Comp 1 4 2 3
## (fctr) (dbl) (dbl) (dbl) (dbl)
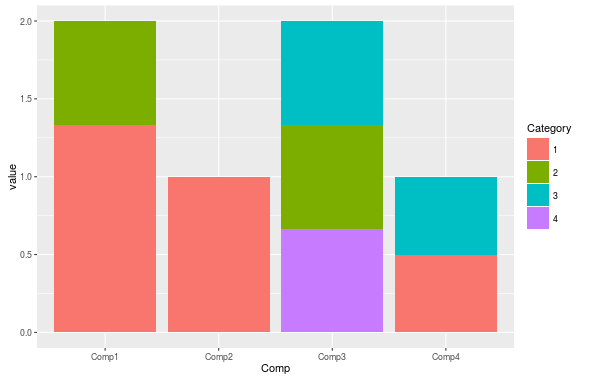
## 1 Comp1 1.333333 0.0000000 0.6666667 0.0000000
## 2 Comp2 1.000000 0.0000000 0.0000000 0.0000000
## 3 Comp3 0.000000 0.6666667 0.6666667 0.6666667
## 4 Comp4 0.500000 0.0000000 0.0000000 0.5000000这首先通过Comp对数据进行分组,然后将函数cat_perc应用于数据帧的子集,并使用给定的Comp。
我将用ggplot2包绘制数据,它要求数据采用所谓的长格式。这意味着要绘制的每个数据点应该对应于数据帧中的一行。(现在的情况是,每行包含4个数据点。)这可以用tidyr包完成,如下所示:
library(tidyr)
plot_data <- gather(plot_data, Category, value, -Comp)
head(plot_data)
## Source: local data frame [6 x 3]
## Groups: Comp [4]
##
## Comp Category value
## (fctr) (chr) (dbl)
## 1 Comp1 1 1.333333
## 2 Comp2 1 1.000000
## 3 Comp3 1 0.000000
## 4 Comp4 1 0.500000
## 5 Comp1 4 0.000000
## 6 Comp2 4 0.000000如您所见,现在每行都有一个数据点,由Comp、Category和相应的value来描述。
绘制数据
现在,所有内容都已读取,我们可以使用ggplot绘制数据。
library(ggplot2)
ggplot(plot_data, aes(x = Comp, y = value, fill = Category)) +
geom_bar(stat = "identity")
https://stackoverflow.com/questions/35700819
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号