
关于正则表达式的回溯
大家好。我有个问题。
在第6级,为什么要回溯到“Welco”?
我认为回溯到‘欢迎’是正确的,在第6级。
已经在第四层使用了“Welcom”吗?
英语写作很难。)
回答 2
Stack Overflow用户
发布于 2016-02-28 21:57:37
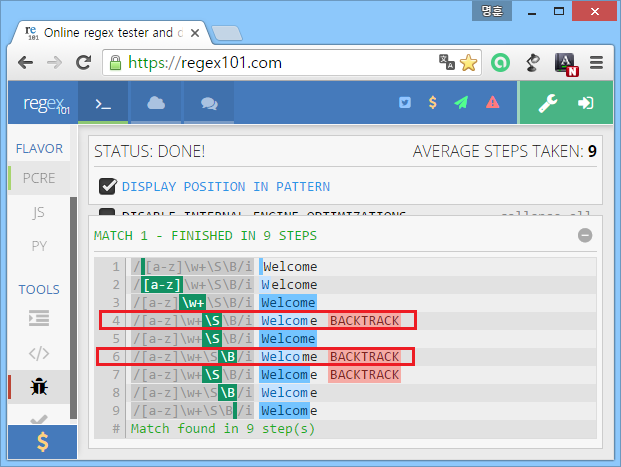
[a-z]\w+\S\B模式不是一个好的模式。为什么?因为相邻的子模式可以相互匹配。这就是为什么在这么短的输入中有3个回溯步骤,具有这样的基本子模式。
现在,一旦您了解子模式的作用,一切都会变得清晰起来。
步骤1:我们在字符串中找到了空位置(regex引擎检查输入字符串中的每个位置)。
步骤2:[a-z]匹配第一个字符W (因为该模式不区分大小写)。
步骤3:\w+与elcome匹配,因为这是文本的单词字符块。所有这些字符都添加到匹配值(Welcome已经在这里!)但仍有一些子模式需要加以匹配。因此,regex引擎继续努力工作。)
步骤4: regex引擎试图为\S (非空白)子模式提供一些文本。它回溯,即产生最后一个字符来测试它是否可以与\S子模式匹配。
第5步:最后一个e满足需求。现在我们在匹配中仍然有Welcome,但是最后一个e“属于”\S子模式。
步骤6:与\S匹配的e后面没有一个非单词边界(因为如果最后一个字符是单词字符,则\B在字符串末尾不匹配)。这个事实使e与\S子模式的匹配无效。因此,regex引擎必须再次回溯以重新容纳\S子模式的值。e不能与\S相匹配,因此,回溯到m。这就是为什么第6步的regex索引就在o之后。
步骤7:\S可以匹配m,所以现在m“属于”\S子模式。
步骤8:\B匹配m和e之间的位置。去吧。
步骤9:到达模式的结束。返回匹配值:Welcom。
Stack Overflow用户
发布于 2016-02-28 14:10:31
+是贪婪的,它试图匹配所有的东西。因此,一旦\w+匹配了整个输入,引擎就会尝试匹配\S并失败,因此它会在前面一步返回并尝试与\w+匹配。它继续这样做,直到找到匹配(或未找到)。
https://stackoverflow.com/questions/35683478
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号