
蜂巢/ Tez作业不会开始
我试图通过从HDFS中的文本文件导入ORC table来在Hive中创建一个。我尝试过多种不同的方式,在网上搜索帮助,不管插入作业不会启动。
我可以将文本文件读取到HDFS,我可以将文本文件读取到Hive,但是不能将文本文件转换为ORC.。
我尝试了许多不同的变体,包括这个可以用来引用这个问题的变体:
method.html
我有一个单节点HDP集群(用于开发)-版本:
HDP-2.3.2.0
(2.3.2.0-2950)
以下是相关的服务版本:
服务版本状态描述
HDFS 2.7.1.2.3安装Apache分布式文件系统
MapReduce2 2.7.1.2.3安装Apache MapReduce (纱线)
安装了Apache MapReduce (纱线)
Tez 0.7.0.2.3安装的Tez是下一代Hadoop查询处理框架,写在纱线上。
安装了用于即席查询的数据仓库系统&大型数据集和表存储管理服务的分析
当我运行这样的SQL时会发生什么(同样,我尝试了许多变体,包括直接来自在线教程):
插入覆盖表,我的汽车选择*从汽车;
我的工作就是这样:
申请总数(申请类型:[],并说明:
提交、接受、运行):1
Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
application_1455989658079_0002 HIVE-3f41161c-b806-4e7d-974e-c18e028d683f TEZ hive root.hive ACCEPTED UNDEFINED 0% N/A它就挂在那里。(从字面上讲,我已经尝试了一个20行示例表,并让它运行了几个小时之后才杀死它)。
我还不是Hadoop专家,我确信这可能是一个配置问题,但我一直无法弄清楚。
我尝试过的所有其他Hive操作,如创建删除表、将文件加载到文本表、选择、所有操作都很好。当我创建一个ORC表时,它就是这样做的。我需要一张兽人桌来满足我的要求。
任何建议都会有帮助。
回答 1
Stack Overflow用户
发布于 2018-10-17 14:40:36
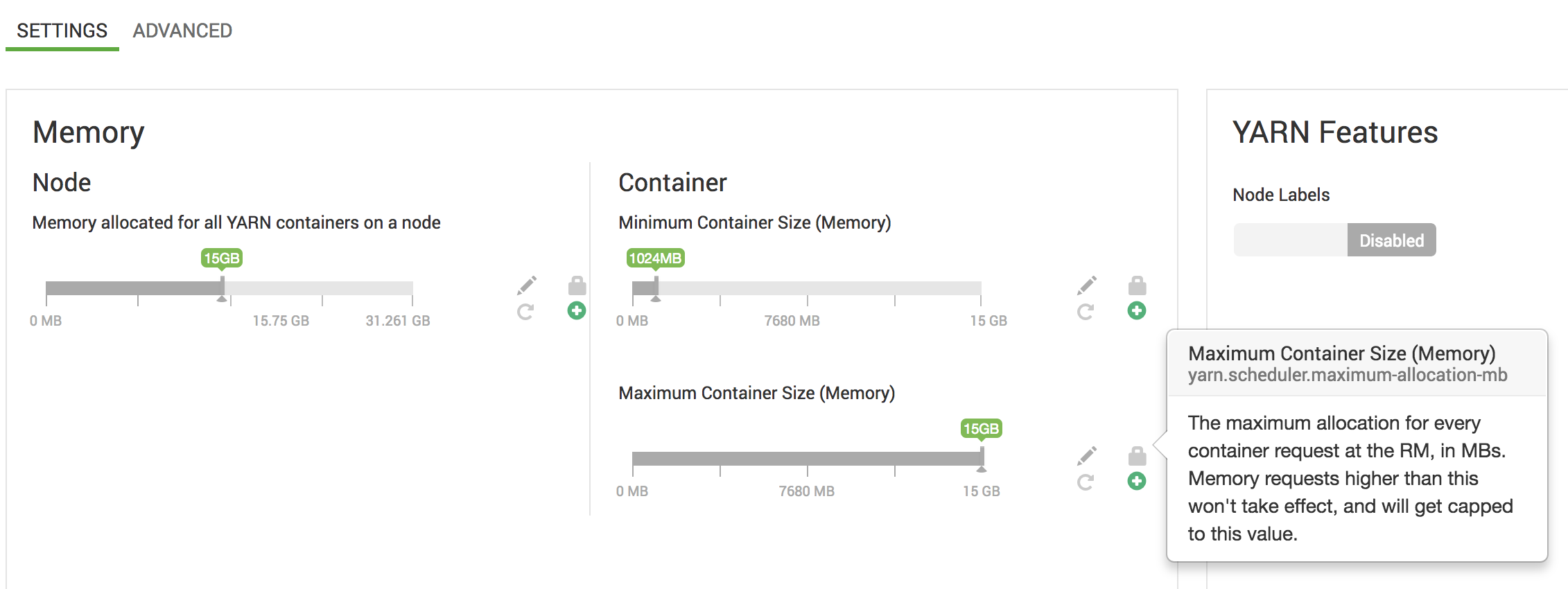
大多数情况下,这与增加Yarn调度能力有关,但如果资源已经被限制,您还可以通过调整TEZ配置中的以下属性,减少单个TEZ任务请求的内存量:
task.resource.memory.mb为了增加集群的容量,您可以在纱线的配置设置中或直接通过Ambari或Cloudera Manager来实现该功能。
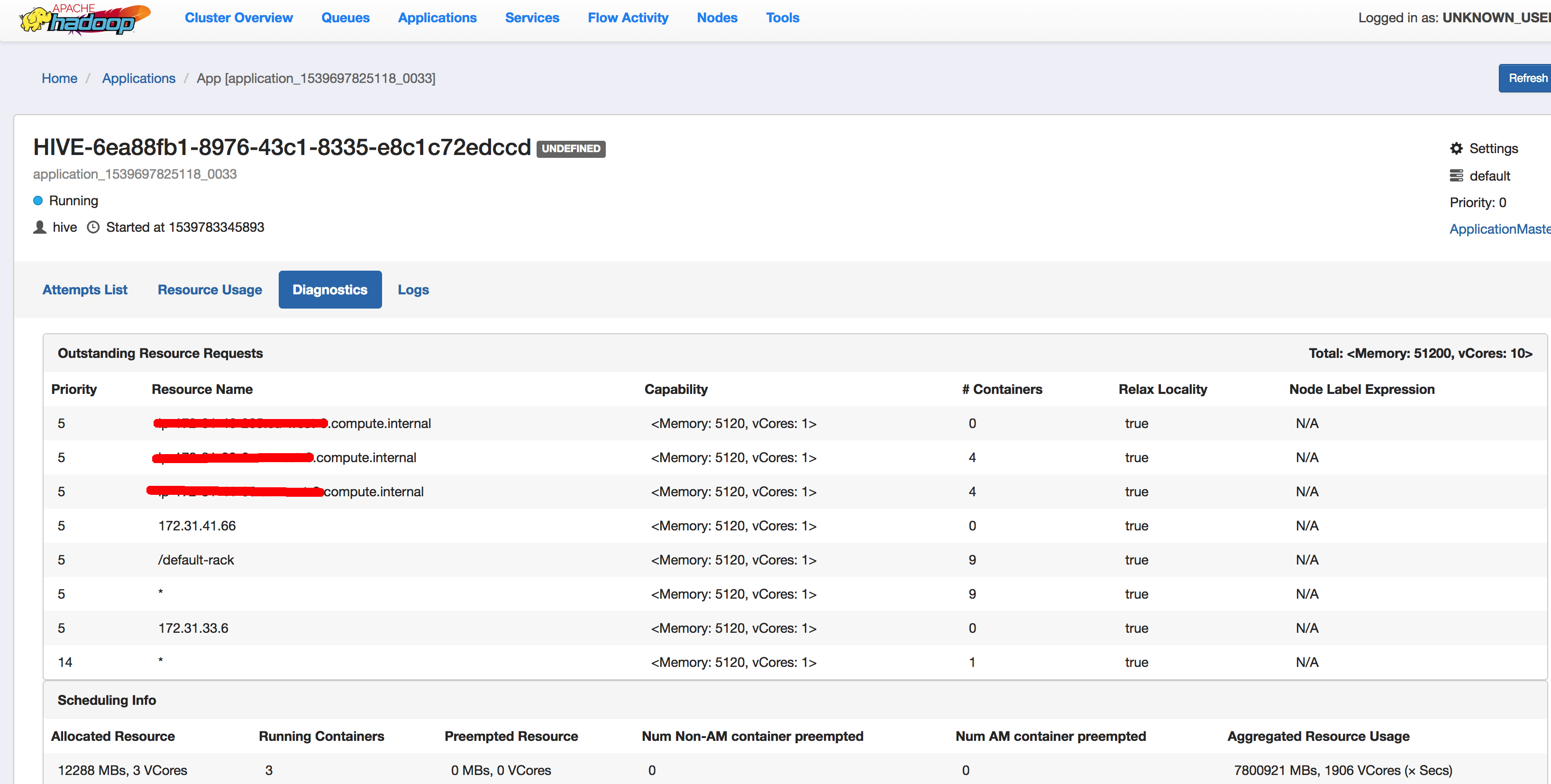
为了监视引擎背后发生的事情,您可以运行并检查特定应用程序的诊断选项卡,在资源分配方面有一些有用的显式消息,特别是当作业被接受并一直挂起时。
https://stackoverflow.com/questions/35527542
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号