
提高正弦/余弦和大阵列的计算速度
对于信号处理,我需要计算比较大的C数组,如下面的代码部分所示。到目前为止,这还不错,不幸的是,实现是缓慢的。“口径数据”的大小约为150 K,需要对不同频率/相位进行计算。有什么方法可以显著提高速度吗?在MATLAB中对逻辑索引做同样的操作要快得多。
我已经尝试过的:
- 利用正弦的taylor近似:无显着性改进。
- 使用std::载体,也没有明显的改善。
代码:
double phase_func(double* calibdata, long size, double* freqscale, double fs, double phase, int currentcarrier){
for (int i = 0; i < size; i++)
result += calibdata[i] * cos((2 * PI*freqscale[currentcarrier] * i / fs) + (phase*(PI / 180) - (PI / 2)));
result = fabs(result / size);
return result;}向你问好,托马斯
回答 6
Stack Overflow用户
发布于 2016-02-19 20:21:30
当为速度优化代码时,第1步是启用编译器优化。我希望你已经这么做了。
第二步是对代码进行分析,并准确地查看时间是如何度过的。如果没有分析,你只是在猜测,最后你可能会试图优化错误的东西。
例如,您的猜测似乎是cos函数是瓶颈。但另一种可能是,角度的计算是瓶颈。下面是我如何重构代码以减少计算角度所花费的时间。
double phase_func(double* calibdata, long size, double* freqscale, double fs, double phase, int currentcarrier)
{
double result = 0;
double angle = phase * (PI / 180) - (PI / 2);
double delta = 2 * PI * freqscale[currentcarrier] / fs;
for (int i = 0; i < size; i++)
{
result += calibdata[i] * cos( angle );
angle += delta;
}
return fabs(result / size);
}Stack Overflow用户
发布于 2016-02-19 20:16:14
好吧,我可能会因为这个答案而被鞭打,但我会用GPU来做这个。因为您的数组似乎不是自引用的,所以对于大型数组来说,最好的加速是通过并行.到目前为止。我不使用MATLAB,但我只是在MathWorks站点上快速搜索了GPU的利用率:
http://www.mathworks.com/company/newsletters/articles/gpu-programming-in-matlab.html?requestedDomain=www.mathworks.com
在MATLAB之外,您可以自己使用OpenCL或CUDA。
Stack Overflow用户
发布于 2016-02-19 19:55:31
您可以尝试使用基于复指数的余弦定义:
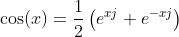
在哪里j^2=-1。
存储exp((2 * PI*freqscale[currentcarrier] / fs)*j)和exp(phase*j)。然后,评估cos(...)将恢复到for循环中的几个产品和添加项,而sin()、cos()和exp()只被称为几次。
实现如下:
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <complex.h>
#include <time.h>
#define PI 3.141592653589
typedef struct cos_plan{
double complex* expo;
int size;
}cos_plan;
double phase_func(double* calibdata, long size, double* freqscale, double fs, double phase, int currentcarrier){
double result=0; //initialization
for (int i = 0; i < size; i++){
result += calibdata[i] * cos ( (2 * PI*freqscale[currentcarrier] * i / fs) + (phase*(PI / 180.) - (PI / 2.)) );
//printf("i %d cos %g\n",i,cos ( (2 * PI*freqscale[currentcarrier] * i / fs) + (phase*(PI / 180.) - (PI / 2.)) ));
}
result = fabs(result / size);
return result;
}
double phase_func2(double* calibdata, long size, double* freqscale, double fs, double phase, int currentcarrier, cos_plan* plan){
//first, let's compute the exponentials:
//double complex phaseexp=cos(phase*(PI / 180.) - (PI / 2.))+sin(phase*(PI / 180.) - (PI / 2.))*I;
//double complex phaseexpm=conj(phaseexp);
double phasesin=sin(phase*(PI / 180.) - (PI / 2.));
double phasecos=cos(phase*(PI / 180.) - (PI / 2.));
if (plan->size<size){
double complex *tmp=realloc(plan->expo,size*sizeof(double complex));
if(tmp==NULL){fprintf(stderr,"realloc failed\n");exit(1);}
plan->expo=tmp;
plan->size=size;
}
plan->expo[0]=1;
//plan->expo[1]=exp(2 *I* PI*freqscale[currentcarrier]/fs);
plan->expo[1]=cos(2 * PI*freqscale[currentcarrier]/fs)+sin(2 * PI*freqscale[currentcarrier]/fs)*I;
//printf("%g %g\n",creall(plan->expo[1]),cimagl(plan->expo[1]));
for(int i=2;i<size;i++){
if(i%2==0){
plan->expo[i]=plan->expo[i/2]*plan->expo[i/2];
}else{
plan->expo[i]=plan->expo[i/2]*plan->expo[i/2+1];
}
}
//computing the result
double result=0; //initialization
for(int i=0;i<size;i++){
//double coss=0.5*creall(plan->expo[i]*phaseexp+conj(plan->expo[i])*phaseexpm);
double coss=creall(plan->expo[i])*phasecos-cimagl(plan->expo[i])*phasesin;
//printf("i %d cos %g\n",i,coss);
result+=calibdata[i] *coss;
}
result = fabs(result / size);
return result;
}
int main(){
//the parameters
long n=100000000;
double* calibdata=malloc(n*sizeof(double));
if(calibdata==NULL){fprintf(stderr,"malloc failed\n");exit(1);}
int freqnb=42;
double* freqscale=malloc(freqnb*sizeof(double));
if(freqscale==NULL){fprintf(stderr,"malloc failed\n");exit(1);}
for (int i = 0; i < freqnb; i++){
freqscale[i]=i*i*0.007+i;
}
double fs=n;
double phase=0.05;
//populate calibdata
for (int i = 0; i < n; i++){
calibdata[i]=i/((double)n);
calibdata[i]=calibdata[i]*calibdata[i]-calibdata[i]+0.007/(calibdata[i]+3.0);
}
//call to sample code
clock_t t;
t = clock();
double res=phase_func(calibdata,n, freqscale, fs, phase, 13);
t = clock() - t;
printf("first call got %g in %g seconds.\n",res,((float)t)/CLOCKS_PER_SEC);
//initialize
cos_plan plan;
plan.expo=malloc(n*sizeof(double complex));
plan.size=n;
t = clock();
res=phase_func2(calibdata,n, freqscale, fs, phase, 13,&plan);
t = clock() - t;
printf("second call got %g in %g seconds.\n",res,((float)t)/CLOCKS_PER_SEC);
//cleaning
free(plan.expo);
free(calibdata);
free(freqscale);
return 0;
}用gcc main.c -o main -std=c99 -lm -Wall -O3编译。使用您提供的代码,在我的计算机上使用size=100000000 8秒,而建议的解决方案的执行时间需要1.5秒.它不那么令人印象深刻,但也不是不可否认的。
所给出的解决方案不涉及在for循环中调用cos of sin。事实上,只有乘法和加法。瓶颈要么是内存带宽,要么是通过平方进行的内存测试和访问(很可能是第一个问题,因为我添加了一个额外的复杂数组)。
关于c中的复数,见:
如果问题是内存带宽,那么就需要并行.直接计算cos会更容易。如果freqscale[currentcarrier] / fs是整数,则可以执行额外的简化。您的问题非常接近于离散余弦变换的计算,现在的技巧接近离散傅里叶变换,而FFTW库非常擅长于计算这些变换。
请注意,由于失去意义,当前代码可以生成innacurate结果:当result较大时,size可能比cos(...)*calibdata[]大得多。使用部分和可以解决这个问题。
https://stackoverflow.com/questions/35513581
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号