
使用熊猫群只是为了删除重复的项目
我确信这是一个基本的问题,但我无法在这里找到正确的路径。
让我们假设像这样的数据,告诉每个人每周吃多少水果:
Name Fruit Amount
1 Jack Lemon 3
2 Mary Banana 6
3 Sophie Lemon 1
4 Sophie Cherry 10
5 Daniel Banana 2
6 Daniel Cherry 4现在假设我只想用matplotlib创建一个酒吧小区,显示整个城镇每周吃水果的总量。要做到这一点,我必须靠水果。
在他的书中,熊猫作者将groupby描述为split-apply-combine操作的第一部分:
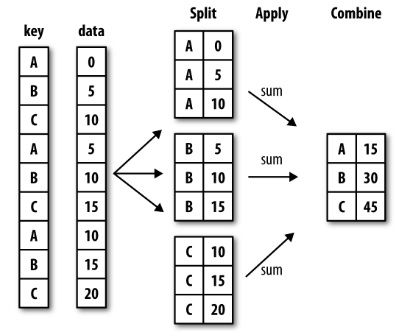
因此,首先,groupby将DataFrame转换为DataFrameGroupBy对象。然后,使用诸如sum这样的方法,将结果组合成一个新的DataFrame对象。太好了,我现在可以创造我的果子了。
但我面临的问题是,当我不想对每个组成员使用sum、diff或应用任何操作时,会发生什么情况。当我只想使用groupby来保持DataFrame每种水果类型只有一行时会发生什么(当然,对于像这个这样简单的例子,我可以只使用unique获得一个水果列表,但这不是重点)。
如果我这样做,groupby的返回是一个DataFrameGroupBy对象,许多与DataFrame一起工作的操作不使用DataFrameGroupBy。
这个问题,我敢肯定,很容易避免,让我头痛。我如何从DataFrame获得一个groupby,而不必应用任何聚合函数?有没有不同的解决办法,甚至没有使用groupby,因为我失去了在翻译?
回答 3
Stack Overflow用户
发布于 2016-02-19 08:21:49
如果您只想要一些行,可以使用first() + reset_index的组合-它将保留每个组的第一行:
import pandas as pd
df = pd.DataFrame({'a': [1, 1, 2], 'b': [1, 2, 3]})
>>> df.groupby(df.a).first().reset_index()
a b
0 1 1
1 2 3Stack Overflow用户
发布于 2016-02-19 09:12:22
这一点让我觉得这可能是你正在寻找的答案:
在没有使用groupby的情况下,是否有不同的解决方法?
如果您只想删除基于Fruit的重复行,那么.drop_duplicates就是最好的选择。
df.drop_duplicates(subset='Fruit')
Name Fruit Amount
1 Jack Lemon 3
2 Mary Banana 6
4 Sophie Cherry 10对于保留哪些行有有限的控制,请参阅docstring。
这比groupby + first更快、更易读。
Stack Overflow用户
发布于 2016-02-19 08:23:28
您可以使用pivot_table来返回DataFrame
In [140]: df.pivot_table(index='Fruit')
Out[140]:
Amount
Fruit
Banana 4
Cherry 7
Lemon 2
In [141]: type(df.pivot_table(index='Fruit'))
Out[141]: pandas.core.frame.DataFrame如果要保留第一个元素,可以定义函数并将其传递给aggfunc参数:
In [144]: df.pivot_table(index='Fruit', aggfunc=lambda x: x.iloc[0])
Out[144]:
Amount Name
Fruit
Banana 6 Mary
Cherry 10 Sophie
Lemon 3 Jack如果不希望Fruit成为索引,也可以使用reset_index
In [147]: df.pivot_table(index='Fruit', aggfunc=lambda x: x.iloc[0]).reset_index()
Out[147]:
Fruit Amount Name
0 Banana 6 Mary
1 Cherry 10 Sophie
2 Lemon 3 Jackhttps://stackoverflow.com/questions/35500425
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号