
深度学习中的音频特征
我发现了一些论文和幻灯片使用深入学习的音频分类。
一些研究采用谱图作为深度学习模型的输入。
我想知道具体和实际的执行情况。
我找到了这张幻灯片。
第67页
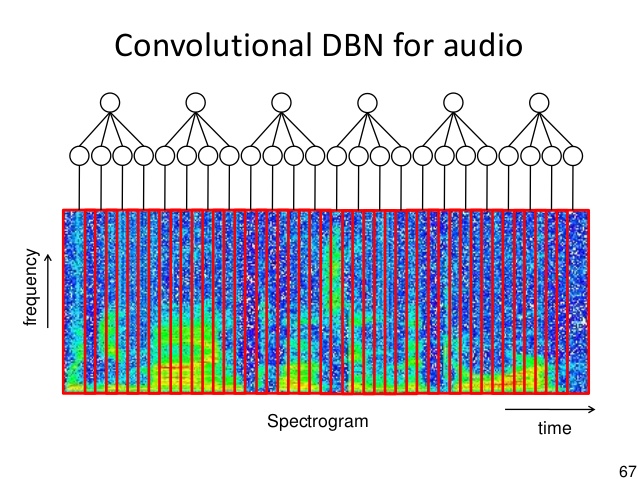
据我所知,第一层的节点数是24,输入是24个不同时间段的谱图。
例如,如果一个音频事件是2.4秒,第一个节点是0~0.1秒的谱图,第二个节点是0.1~0.2秒的谱图.
我误解了吗?
我的问题是:如果有一个3.0秒的音频事件,如何分类?
回答 3
Stack Overflow用户
发布于 2017-05-24 12:49:16
利用卷积神经网络对时间序列数据进行分类。卷积神经网络与人工神经网络基本相同。唯一的区别是,ANN的输入必须首先由转换为,以提取特定的特征。以直观的方式,卷积运算基本上突出了某些数据的具体特征。这是最好的描述通过闪光灯通过不同的部分图像。通过这样做,我们可以突出图像的具体特征。
这就是CNN的主要想法。它本身就是为了提取空间特征而设计的。卷积运算通常是叠加的,这意味着你有(行、列、维),所以卷积的输出是三维的。这个过程的缺点是计算时间很长。为了减少这种情况,我们需要池或下采样,这基本上可以减少特征检测器的大小,而不会丢失基本的特征/信息。例如,在汇集之前,您有6,6个矩阵中的12个作为特征检测器。在汇集后,您有12个大小为3,3的卷积数据。您可以在平坦之前一遍又一遍地执行这两个步骤,基本上将所有这些压缩到(n,1)维数组中。之后,你可以做正常的安步骤。
总之,对时间序列数据进行分类的步骤可以使用CNN来完成。以下是几个步骤:
1.Convolution
2.Pooling
3.Flattening
4.完全连接(正常ANN步骤)
您可以添加卷积和池层尽可能多,但要注意培训时间。这是我最喜欢的尤塔伯,西拉杰·拉瓦尔的视频。顺便提一下,我建议你使用喀拉斯进行深度学习。放下最容易使用的深层次学习库。希望能帮上忙。
Stack Overflow用户
发布于 2016-09-21 19:09:55
您应该使用卡尔迪。反恐委员会负责处理时间分辨率。
Stack Overflow用户
发布于 2017-12-15 09:43:42
我训练了一名CNN来检测录音中所说的语言。目前它支持176种语言,准确率为98.8%。我的GitHub帐户上有一本评论很好的朱庇特笔记本:口语分类器。
我想这就是你要找的。我学到的一些东西包括:
- 该体系结构不需要重复使用,因为时间可以在x轴上编码。对于一个非经常性的CNN来说,你输入的长度必须固定下来。
- 光谱图在许多方面与照片有语义上的不同。流行的架构,很好地为照片工作,可能是完全过分的光谱图。
- 分别对x和y进行不同分辨率的实验。我的第一个假设是时间轴需要比频率轴更高的分辨率,这在我的用例中是错误的。
- 使用mel-谱图给出更高的分辨率和更低的频率.我们的听力是指数级的,而不是线性的。
https://stackoverflow.com/questions/35169706
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号