
SAS :总结数据
SAS :总结数据
提问于 2016-02-02 11:08:21
我有一个给定的数据集:
Policy_Number,var1,var2,var3,Exposure
1,B,H,J,191
2,B,F,Unknown,174
3,C,Unknown,I,153
4,B,G,L,192
5,Unknown,E,Unknown,184
6,D,E,K,113
7,C,Unknown,I,140
8,A,H,I,133
9,C,F,I,194
10,Unknown,G,Unknown,105
11,B,H,L,172
12,A,Unknown,I,198
13,D,E,K,155
14,Unknown,G,K,177
15,B,H,Unknown,100
16,D,Unknown,J,176
17,B,E,I,112
18,Unknown,E,J,192
19,C,Unknown,K,146
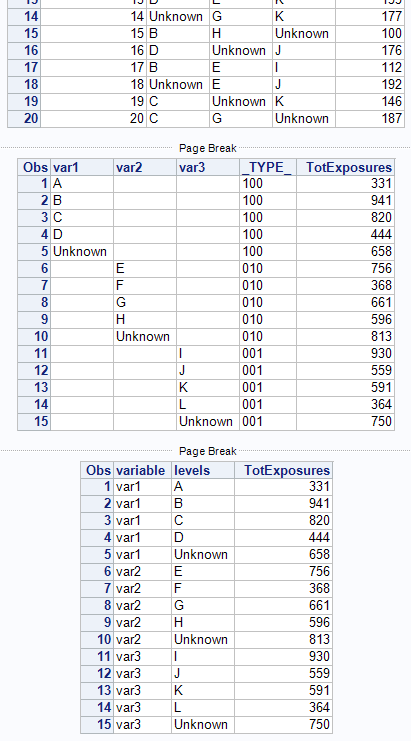
20,C,G,Unknown,187我希望通过使用PROC方法或概要将给定的数据转换为以下形式:
Variables Levels Tot_Exposures
Var1 A 331
Var1 B 941
Var1 C ...
Var1 D ...
Var1 Unknown ...
Var2 E ...
Var2 F ...
Var2 G ...
Var2 H ...
Var2 Unknown ...
Var3 I ...
Var3 J ...
Var3 K ...
Var3 L ...
Var3 Unknown ...Tot_Exposure返回我想要的每个VariableName的总曝光量,这是一个汇总表。请帮帮我。
编辑:我已经尝试过proc方法,但我希望它能一步一步地执行。我分三步做的。得到了像图像一样的输出。
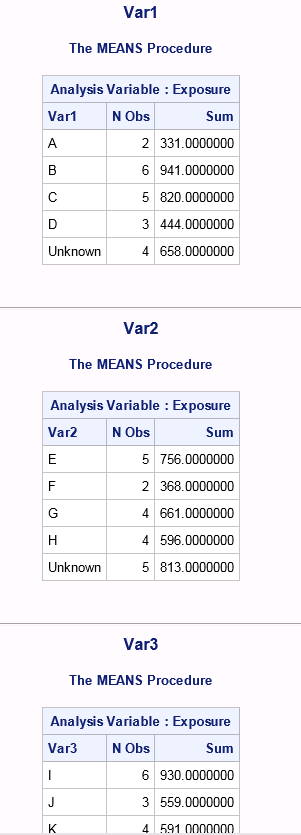
守则是这样的:
data try2;
infile 'complex.csv' dsd dlm = ',' FIRSTOBS = 2;
Length Policy_Number Var1 $ 10 Var2 $ 10 Var3 $ 10 Exposure 3;
input Policy_Number $ Var1 $ Var2 $ Var3 $ Exposure;
run;
proc sort data = try2;
by Exposure;
run;
proc means data = try2 SUM;
class Var1;
var exposure;
output out = want;
title ' Var1';
run;
proc means data = try2 SUM;
class Var2;
var exposure;
output out = want2;
title 'Var2';
run;
proc means data = try2 SUM;
class Var3;
var exposure;
output out = want3;
title 'Var3';
run;回答 3
Stack Overflow用户
回答已采纳
发布于 2016-02-02 12:49:24
您可以在一个PROC摘要步骤中总结所有三个变量,但是输出与您指定的不完全相同。但是,这可以通过对PROC摘要输出的数据步骤操作来实现。我在CLASS语句中使用MLF选项将所有类变量“转换”为字符。您没有,但它很有用,因为类变量可以是数字的任何一个字符。
data exp;
infile cards dsd firstobs=2;
input Policy_Number (var1-var3) ($) Exposure;
cards;
Policy_Number,var1,var2,var3,Exposure
1,B,H,J,191
2,B,F,Unknown,174
3,C,Unknown,I,153
4,B,G,L,192
5,Unknown,E,Unknown,184
6,D,E,K,113
7,C,Unknown,I,140
8,A,H,I,133
9,C,F,I,194
10,Unknown,G,Unknown,105
11,B,H,L,172
12,A,Unknown,I,198
13,D,E,K,155
14,Unknown,G,K,177
15,B,H,Unknown,100
16,D,Unknown,J,176
17,B,E,I,112
18,Unknown,E,J,192
19,C,Unknown,K,146
20,C,G,Unknown,187
;;;;
run;
proc summary data=exp descendtypes chartype;
class var: / mlf;
ways 1;
freq Exposure;
output out=test(rename=(_freq_=TotExposures));
run;
data want;
length variable $32 levels $8;
set test;
array v[*] var1-var3;
drop var1-var3 i _type_;
i = indexc(_type_,'1');
variable = vname(v[i]);
levels = v[i];
run;
Stack Overflow用户
发布于 2016-02-02 11:20:18
很抱歉,把我的旧答案带到一个新的职位,但取决于您需要具体的proc摘要,我的旧方法将为您计算这一点。
如果您将最后一个SQL部分(我刚刚将其添加到)交换到:
proc sql;
create table OUT as
select VARIABLENAME
, VARIABLEVALUE
, sum(EXPOSURE)
from
GET_MAX
group by 1,2
;quit;Stack Overflow用户
发布于 2016-02-02 13:54:44
这将很容易地处理350个变量,4500万条记录将需要一段时间,但是PROC摘要也可以轻松地处理。变量级别需要定义长度等于或大于所有类变量的最长格式化值。你可以在另一个问题中问这是怎么做到的。
data exp;
infile cards dsd firstobs=2;
input Policy_Number (var1-var3) ($) Exposure;
arbitraryname243 = rank(first(var1));
arbitraryname4 = rantbl(123,.4);
arbitraryname36 = rank(first(var3));
cards;
Policy_Number,var1,var2,var3,Exposure
1,B,H,J,191
2,B,F,Unknown,174
3,C,Unknown,I,153
4,B,G,L,192
5,Unknown,E,Unknown,184
6,D,E,K,113
7,C,Unknown,I,140
8,A,H,I,133
9,C,F,I,194
10,Unknown,G,Unknown,105
11,B,H,L,172
12,A,Unknown,I,198
13,D,E,K,155
14,Unknown,G,K,177
15,B,H,Unknown,100
16,D,Unknown,J,176
17,B,E,I,112
18,Unknown,E,J,192
19,C,Unknown,K,146
20,C,G,Unknown,187
;;;;
run;
proc transpose data=exp(obs=0 drop=policy_number exposure) out=varlist;
var _all_;
run;
Proc sql noprint;
select nliteral(_name_) into :classvars separated by ' ' from varlist;
quit;
%put NOTE: &=classvars;
proc summary data=exp descendtypes chartype;
class &classvars / mlf;
ways 1;
freq Exposure;
output out=test(rename=(_freq_=TotExposures));
run;
data want(keep=Variable levels totexposures);
length variable $32 levels $8;
set test;
array v[*] &classvars;
i = indexc(_type_,'1');
variable = vname(v[i]);
levels = v[i];
run;页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/35151787
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号