
基于隐式矢量化的HPC编程语言
是否有依赖于隐式矢量化的编程语言或语言扩展?
对于SSE4.1、AVX、AVX2 (不管有没有FMA3 3/4),我需要做一些积极的假设来生成良好的DLP/矢量化代码。
在过去的10年里,我很高兴依靠英特尔的本质来编写我的HPC内核,并显式地向量化。同时,我经常对C/C++编译器(GCC、clang、LLVM等)生成的DLP代码的质量感到失望,如果您问我,我可以发布具体的示例。
从本质指南中可以清楚地看到,为现代平台编写“手动”HPC内核的内在特性不再是一个可持续的选择,除非我有一群程序员。太多的版本和组合: SSE4.1,AVX,AVX2,AVX512+flavors,FMA,SP,DP,半精度?如果我的目标平台是自2012年以来最普遍的平台,那它就是不可持续的。
我最近试用了英特尔OpenCL离线编译器(CPU)。我编写了内核"a la CUDA“(即标量代码、隐式矢量化),令我惊讶的是生成的程序集是非常好的矢量化的!(Skylake,AVX2 + FMA,在SP中)我遇到的唯一限制是缺乏用于数据缩减/互操作的内置函数--不依赖共享内存的通信(这将转化为CPU水平添加,或者洗牌+ min/max操作)。
正如克莱门斯和舒伯斯所指出的,离线编译器并不是真正的解决方案,除非我没有完全接受OpenCL。或者我黑我的调用者代码以遵守生成的程序集的调用约定,其中包括我不需要的参数,比如ndrange。对我来说,完全接受OpenCL也不是一种选择,因为对于TLP,我依赖于OpenMP和线程(对于ILP,我依赖于硬件)。
更新
首先,值得回顾的是,隐式向量化和自动向量化并不是一回事。事实上,我对自动矢量化失去了希望(如前所述)。在隐式矢量化中没有。
下面的答案之一是询问一些代码示例。这里 I提供了一个内核在三维结构化块上为NSE的对流项实现三阶迎风方案的代码示例。值得一提的是,这是一个微不足道的例子,因为不需要SIMD之间的合作/沟通。
回答 2
Stack Overflow用户
发布于 2016-02-08 09:22:59
英特尔SPMD程序编译器。
目前,最好的选择是Intel SPMD程序编译器。ISPC是一个开源编译器,它的编程模型依赖于隐式矢量化(从Intel OpenCL SDK文档中借用的术语)来输出矢量化汇编代码。ISPC将源代码映射到SSE4.1、AVX、AVX2、KNC和KNL的SP/DP的AVX512指令。ISPC的后端是LLVM。
对于CFD内核,它提供了无与伦比的性能。对于必须是标量的代码部分,可以简单地将"uniform“关键字添加到相关变量中。有内置功能的车道间通信,如洗牌,广播和reduce_add等.
为什么与其他C++编译器相比,ISPC速度如此之快?我的猜测是,因为C/C++编译器假定没有任何东西可以向量化,除非有明显的相反的证据。ISPC假设每一行代码都(独立)由所有SIMD车道执行,除非另有规定。
我不知道为什么ISPC还没有被广泛接受。也许是因为他的幼年阶段,但它已经显示出强大的能力(恩布里,OSPray)在CG/科学可视化社区。ISPC是编写HPC内核的一个很好的选择,因为它似乎很好地弥合了性能-生产力差距。
基准测试
对于问题中引用的平凡核示例,使用GCC 4.9.X和ISPC1.8.2得到了如下结果。性能按每个周期的失败来报告。
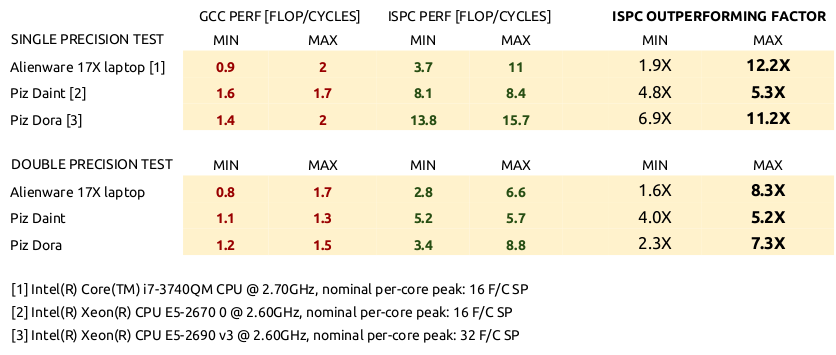
这里没有报告ICC的结果(就可访问性而言,向免费和开放源代码的编译器报告ICC是否100%公平?)尽管如此,在本案中,国际刑事法院对GCC报告的最大收益约为4X,因此不影响ISPC的优势。
Stack Overflow用户
发布于 2016-02-02 04:54:07
请注意,如果没有数学或代码示例,很难知道这里的最佳答案是什么。如果您提供了一个代码示例,我将尝试用下面提到的一些方言来实现它。
福特兰90
Fortran 90+冒号符号是实现隐式矢量化的好方法,尽管我怀疑如果您是C本质类程序员,Fortran是不愿意使用的。
关于这个主题的一个合理的信息来源是fortran90.org。
OpenMP 4.0
SIMD 4.0引入了SIMD关键字,这迫使编译器将代码向量化。你应该把它作为本质的另一种选择。
OpenMP 4.0 pragma omp simd online有很多例子,但其中一个非常简单的例子是使用OpenMP4.0在程序中启用SIMD。
显然,OpenMP的最终权威是最新的规范:OpenMP应用程序编程接口版本4.5。
CilkPlus
由于您已经表示愿意编写低于ISO标准的代码,您可能愿意使用英特尔编译器和GCC支持的C/C++ CilkPlus扩展(以及可能的Clang/LLVM,但我尚未验证)。
有关详细信息,请参阅使用Intel Cilk™Plus的最佳实践和CilkPlus主页。
OpenCL
理论上,OpenCL是另一个很好的选择,但在实践中,它似乎不那么令人信服。我本人并不是OpenCL用户,但我与OpenCL编程指南的一位作者合作,我认为他是一个可靠的来源。
自动矢量化
如果所有这些都失败了,Intel 16编译器会完成相当不错的自动矢量化工作,但是您必须阅读opt报告,在许多情况下使用restrict和__assume_aligned。
使用Intel /C++实现自动矢量化时,最好的起点是-qopt-report编译器选项。这通常会告诉你什么是向量化的,什么不是,以及为什么。您可能需要使用不同的分配器((备忘录)列出相关选项),然后在内核中使用__assume_aligned。如果使用第二代英特尔Xeon处理器(又名骑士登陆)或其他支持它们的产品,矢量依赖可能更难缓解,尽管AVX-512 AVX指令可能会有所帮助。
Cray编译器也能很好地自动生成,但仅限于访问Cray超级计算机的用户。
对于那些好奇的人来说,我对这些编译器的乐观是基于NWChem核获得的结果。最好的结果是使用Fortran 77,OpenMP 3/4和使用其他编译器指令,但至少没有处理器特定的代码。C99内核的矢量化足够好。
免责声明
我在英特尔的研究/探索能力工作。我不从事任何软件产品的工作,但我可以从编译团队中的专家那里学习。
https://stackoverflow.com/questions/35127888
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号