
我如何分析混淆矩阵?
当我打印出科学知识-学习的混乱矩阵,我收到一个非常巨大的矩阵。我想分析一下什么是真正的积极,真正的消极等等。我怎么做呢?我的混乱矩阵就是这样的。我希望更好地理解这一点。
[[4015 336 0 ..., 0 0 2]
[ 228 2704 0 ..., 0 0 0]
[ 4 7 19 ..., 0 0 0]
...,
[ 3 2 0 ..., 5 0 0]
[ 1 1 0 ..., 0 0 0]
[ 13 1 0 ..., 0 0 11]]回答 3
Stack Overflow用户
发布于 2016-01-28 13:34:28
你的问题还不明确。“假阳性”、“真实否定”--这些都是只为二进制分类定义的术语。阅读有关混淆矩阵定义的更多信息。
在这种情况下,混淆矩阵是维数N。每个对角线表示,对于条目(i,i)的情况下,预测是i,结果也是i。任何其他非对角线条目都表示预测为i而结果为j的错误。在这种情况下,没有“肯定”和“否定”的意思。
您可以使用np.diagonal轻松地找到诊断元素,然后很容易将它们相加。错误情况的和是矩阵的和减去对角的和。
Stack Overflow用户
发布于 2016-01-28 13:31:11
真阳性、假阳性等术语指的是二进制分类。然而,你的混淆矩阵的维数比两个维度大。因此,你只能谈论已知在第一组中的观察的数量,但是预测是在组j中(混乱矩阵的定义)。
Stack Overflow用户
发布于 2016-08-31 09:25:43
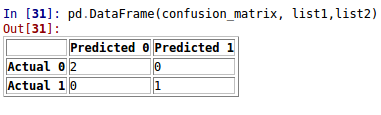
方法1:二进制分类
from sklearn.metrics import confusion_matrix as cm
import pandas as pd
y_test = [1, 0, 0]
y_pred = [1, 0, 0]
confusion_matrix=cm(y_test, y_pred)
list1 = ["Actual 0", "Actual 1"]
list2 = ["Predicted 0", "Predicted 1"]
pd.DataFrame(confusion_matrix, list1,list2)
方法2:多类分类
虽然sklearn.metrics.confusion_matrix提供了一个数字矩阵,但您可以使用以下方法生成一个“报告”:
import pandas as pd
y_true = pd.Series([2, 0, 2, 2, 0, 1, 1, 2, 2, 0, 1, 2])
y_pred = pd.Series([0, 0, 2, 1, 0, 2, 1, 0, 2, 0, 2, 2])
pd.crosstab(y_true, y_pred, rownames=['True'], colnames=['Predicted'], margins=True)其结果是:
Predicted 0 1 2 All
True
0 3 0 0 3
1 0 1 2 3
2 2 1 3 6
All 5 2 5 12这使我们能够看到:
- 对角线元素显示每个类的正确分类数:类0、1和2的3、1和3。
- 非对角线元素提供了错误分类:例如,2类中的2种被错误分类为0,0类中没有一种被误归为2,等等。
- 来自“所有”小计的
y_true和y_pred中每个类的分类总数。
此方法也适用于文本标签,对于数据集中的大量示例也可以扩展,以提供百分比报告。
https://stackoverflow.com/questions/35062665
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号