
随机森林调整-树的深度和树数
关于调整随机森林分类器,我有一个基本的问题。树的数量和树的深度有什么关系吗?树的深度是否一定要小于树的数目?
回答 4
Stack Overflow用户
发布于 2019-03-16 06:10:46
我同意提姆的观点,树数和树深之间没有拇指比例。一般来说,你想要尽可能多的树来改善你的模型。更多的树也意味着更多的计算成本,在一定数量的树之后,改进是微不足道的。正如您在下图中所看到的,在某个时候,即使我们增加了树的no,错误率也没有明显的提高。
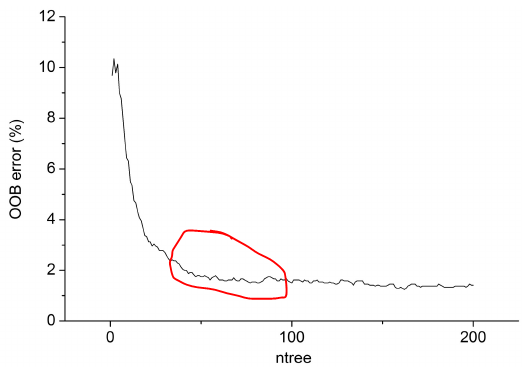
树的深度意味着你想要的树的长度。更大的树可以帮助您传递更多的信息,而较小的树给出的info.So深度不那么精确,应该足够大,以便将每个节点拆分到所需的观察数。
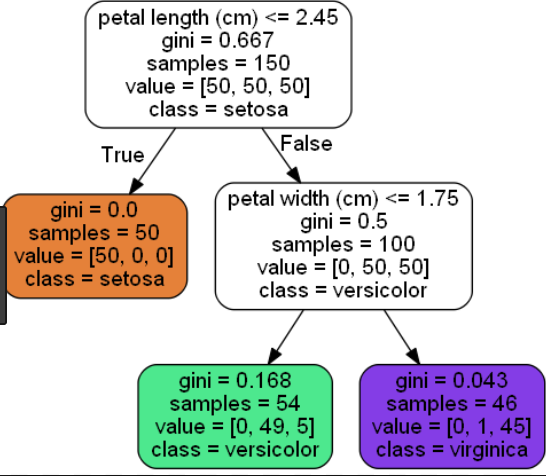
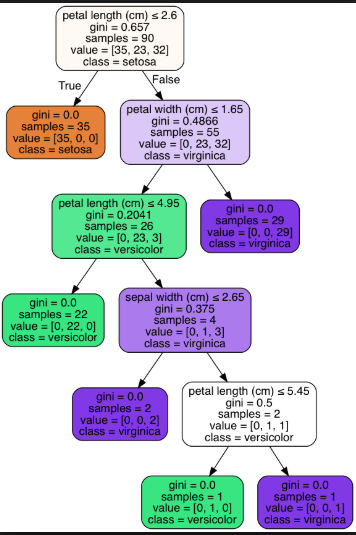
下面是用于虹膜数据集的短树(叶node=3)和长树(叶node=6)的示例:与长树(叶node=6)相比,短树(叶node=3)提供的信息不太精确。
短树(叶node=3):
长树(叶node=6):
Stack Overflow用户
发布于 2016-01-26 10:44:56
对于大多数实际问题,我同意蒂姆的观点。
然而,当集合误差作为附加树的函数收敛时,其他参数确实会产生影响。我想限制树的深度通常会使集合更早一点收敛。我很少摆弄树的深度,好像计算时间被降低了一样,它不提供任何其他的奖励。降低引导样本大小既提供了更低的运行时间,也提供了更低的树相关性,因此在可比较的运行时,通常具有更好的模型性能。一个没有提到的技巧:当RF模型解释的方差小于40%(看似有噪声的数据)时,可以将样本大小降低到10-50%,并将树增加到例如5000(通常不必要的多)。集合误差将作为树的函数在以后收敛。但是,由于树的相关性较低,该模型具有更强的鲁棒性,并将达到较低的OOB误差水平。
您可以在下面看到samplesize提供最好的长期收敛,而max节点从较低的点开始,但收敛较少。对于这种噪声数据,限制最大节点仍然比默认RF更好。对于低噪声数据,通过降低最大节点或样本大小来减小方差,并不会由于缺乏拟合而使偏差增加。
对于许多实际情况,只要你能解释10%的方差,你就会放弃。因此,默认RF通常很好。如果你的量化者,谁可以打赌数百或数千的立场,5-10%的解释方差是可怕的。
绿色曲线是一些树的深度,但不是精确的最大节点。
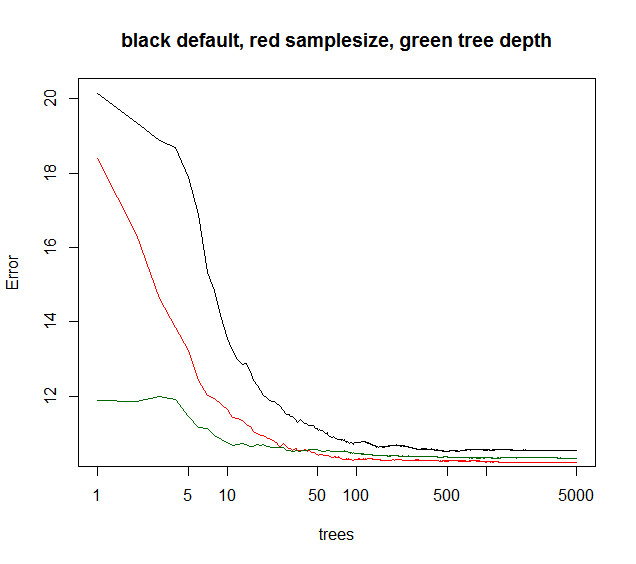
library(randomForest)
X = data.frame(replicate(6,(runif(1000)-.5)*3))
ySignal = with(X, X1^2 + sin(X2) + X3 + X4)
yNoise = rnorm(1000,sd=sd(ySignal)*2)
y = ySignal + yNoise
plot(y,ySignal,main=paste("cor="),cor(ySignal,y))
#std RF
rf1 = randomForest(X,y,ntree=5000)
print(rf1)
plot(rf1,log="x",main="black default, red samplesize, green tree depth")
#reduced sample size
rf2 = randomForest(X,y,sampsize=.1*length(y),ntree=5000)
print(rf2)
points(1:5000,rf2$mse,col="red",type="l")
#limiting tree depth (not exact )
rf3 = randomForest(X,y,maxnodes=24,ntree=5000)
print(rf2)
points(1:5000,rf3$mse,col="darkgreen",type="l")Stack Overflow用户
发布于 2016-01-28 23:24:35
的确,一般说来,更多的树木将导致更好的准确性。然而,更多的树也意味着更多的计算成本,在一定数量的树之后,改进是微不足道的。Oshiro等人的一篇文章。(2012年)指出,根据对29个数据集的测试,在128棵树之后,没有明显的改善(这与索伦的图表相一致)。
对于树的深度,标准随机森林算法不需要剪枝就能长出完整的决策树。单一的决策树确实需要修剪以克服过度拟合的问题。然而,在随机森林中,通过随机选择变量和OOB动作来消除这一问题。
参考资料: Oshiro,T.M.,Perez,P.S.和Baranauskas,J.A.,2012年7月。一个随机森林里有多少棵树?在MLDM中(第154-168页)。
https://stackoverflow.com/questions/34997134
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号