
我的k-NN分类器工作正常吗?
我正在做一个项目,我想在fisher的虹膜数据集上使用k-NN分类。我在下面介绍我的k分类MATLAB代码:
rng default;
% k-NN classifier
indices = crossvalind('Kfold',species);
cp = classperf(species);
% k = 1
for i = 1:5
test = (indices == i);
train = ~test;
class = knnclassify(meas(test,:),meas(train,:),species(train,:));
classperf(cp(:),class,test);
end
fprintf('The k-NN classification error rate for k = 1 is: %f\n', cp.ErrorRate);
fprintf('Program paused. Press enter to continue.\n');
pause
% k = 3
for i = 1:5
test = (indices == i);
train = ~test;
class = knnclassify(meas(test,:),meas(train,:),species(train,:),3);
classperf(cp(:),class,test);
end
fprintf('The k-NN classification error rate for k = 3 is: %f\n', cp.ErrorRate);
fprintf('Program paused. Press enter to continue.\n');
pause
% k = 5
for i = 1:5
test = (indices == i);
train = ~test;
class = knnclassify(meas(test,:),meas(train,:),species(train,:),5);
classperf(cp(:),class,test);
end
fprintf('The k-NN classification error rate for k = 5 is: %f\n', cp.ErrorRate);
fprintf('Program paused. Press enter to continue.\n');
pause我怀疑cp.ErrorRate对于所有k= 1,3,5都是一样的。
对于k= 1,3,5,这是接受状态还是应该不同?如果是这样的话,为了完成我的任务,我需要更改什么代码呢?
回答 1
Stack Overflow用户
发布于 2016-01-24 20:22:32
你的观察其实离事实不远。如果您查看Iris数据集的图,您会发现数据实际上是可分离的:
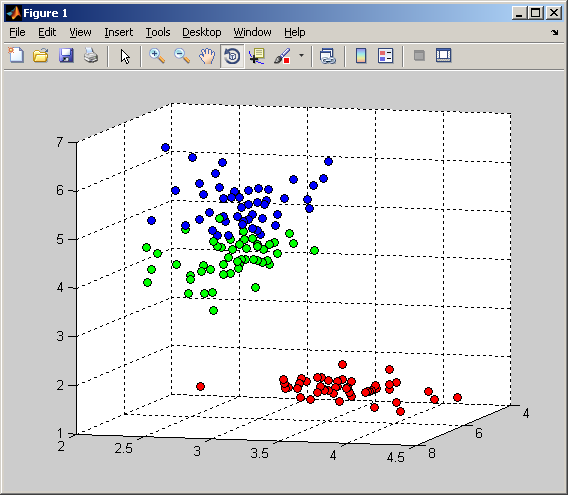
因此,如果您选择一个数据项,您几乎总是可以使用1、3和5个邻居对其进行非常精确的分类。在这些情况下,错误率将非常小。当使用更多的邻居时,这一速度会增加:
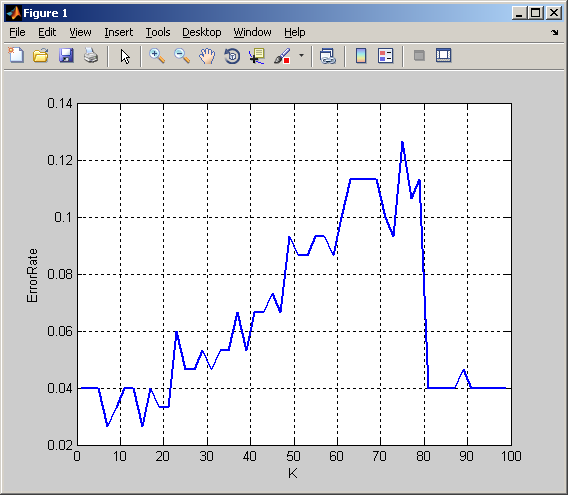
...but如果只使用一个功能来分类数据,特别是不能按照自己的特性将数据很好地分开的特性,那么图看起来就会有所不同(这里我只根据第二个特性对数据进行分类):
但是!,首先,您需要对代码进行一些更正。
每次执行classperf(cp(:),class,test);时,都会更新以前的cp结构。只要您在循环通过您的折叠,但当您进入下一个实验的另一个K值,您需要重新初始化cp结构!否则,下一次实验的结果将被先前的统计数据所偏倚。
看看矩阵cp.CountingMatrix。它包含关于已经分类的数据点的confusion信息,同时在折叠上进行迭代。调用cp.ErrorRate时,将根据此矩阵计算错误。如果没有在每个循环之后重新初始化它,那么下一个实验的统计信息将被添加到以前实验的结果中(我只从矩阵中取了3行):
k = 1; i = 1;
10 0 0
0 10 0
0 0 10
k = 1; i = 2;
20 0 0
0 19 0
0 1 20
k = 1; i = 3;
30 0 0
0 28 0
0 2 30
k = 1; i = 4;
40 0 0
0 37 1
0 3 39
k = 1; i = 5;
50 0 0
0 47 3
0 3 47
k = 3; i = 1;
60 0 0
0 57 3
0 3 57 % is biased by the first experiment下面是我的代码,您可以在这里看到cp的重新初始化。
rng default;
load fisheriris;
fold_number = 5;
indices = crossvalind('Kfold',species, fold_number);
val = 1:2:100;
err_arr = [];
for k=val
cp = classperf(species); %!!! reinitialize the cp-structure
for i = 1:fold_number
test = (indices == i);
train = ~test;
class = knnclassify(meas(test,:),meas(train,:),species(train), k);
%class = knnclassify(meas(test,2),meas(train,2),species(train), k); %to experiment only with the 2nd feature
classperf(cp,class,test);
end
err_arr = [err_arr; cp.ErrorRate];
end
plot(val, err_arr, 'LineWidth', 2);
grid on;
xlabel('K');
ylabel('ErrorRate');https://stackoverflow.com/questions/34974911
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号