
基于密度的代表聚类
我正在寻找一种方法来执行基于密度的聚类。与DBSCAN不同的是,生成的集群应该具有代表性。Mean-Shift似乎满足了这些需求,但不足以满足我的需求。我已经研究了一些子空间聚类算法,并且只找到了使用代表的CLIQUE,但是这个部分不是在Elki中实现的。
回答 2
Stack Overflow用户
发布于 2016-01-12 20:51:18
正如我在关于您问题的上一次迭代的评论中所指出的,https://stackoverflow.com/questions/34720959/dbscan-java-library-with-corepoints
基于密度的集群并不是假定存在一个中心或代表性的。
考虑以下示例来自维基百科用户的图片 (BY-CC-SA3.0):
{kind=link}
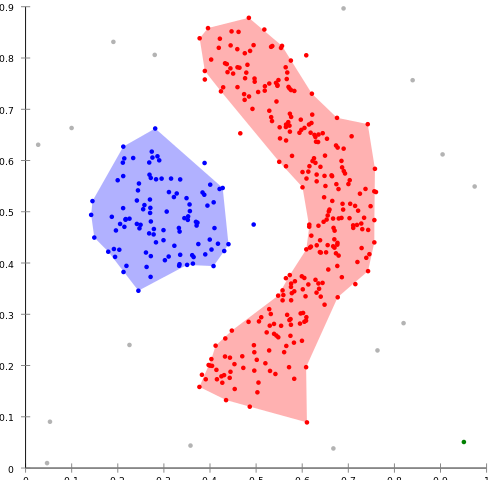
哪个对象应该是红色集群的代表?
基于密度的聚类就是寻找“任意形状”的聚类。这些都没有一个有意义的单一代表对象。它们不是要“压缩”您的数据--这不是矢量量化方法,而是结构发现。但是,这是如此复杂结构的性质,不能简化为一个单一的代表。这样一个簇的适当表示是簇中所有点的集合。对于二维的几何理解,你也可以计算凸包,例如,得到一个区域,如图中的区域。
选择有代表性的对象是另一项任务。这并不是发现这种结构所必需的,因此这些算法不计算有代表性的对象--这将浪费CPU。
Stack Overflow用户
发布于 2016-01-14 08:55:16
您可以选择密度最高的对象作为集群的代表。
对DBSCAN进行相当容易的修改,以存储每个对象的邻居计数。
但是正如Anony-Mousse提到的那样,这个目标可能是一个相当糟糕的选择。基于密度的聚类并不是为了产生有代表性的对象.
您可以尝试AffinityPropagation,但它也不会很好地扩展。
https://stackoverflow.com/questions/34753287
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号