
三层神经网络陷入局部极小化
三层神经网络陷入局部极小化
提问于 2016-01-03 19:27:55
我在Python中编写了一个基于本教程的3层神经网络,用于玩摇滚、纸张、剪刀,样本数据使用-1表示岩石,0用于纸张,1用于剪刀,以及类似于本教程中的数组。在每次运行时,我的函数似乎被困在相对最小值中,我正在寻找一种方法来补救这个问题。程序在下面。
#math module
import numpy as np
#sigmoid function converts numbers to percentages(between 0 and 1)
def nonlin(x, deriv = False):
if (deriv == True): #sigmoid derivative is just
return x*(1-x)#output * (output - 1)
return 1/(1+np.exp(-x)) #print the sigmoid function
#input data: using MOCK RPS DATA, -1:ROCK, 0:PAPER, 1:SCISSORS
input_data = np.array([[1, 1, 1],
[0, 0, 0],
[-1, -1, -1],
[-1, 1, -1]])
#also for training
output_data = np.array([[1],
[0],
[-1],
[1]])
#random numbers to not get stuck in local minima for fitness
np.random.seed(1)
#create random weights to be trained in loop
firstLayer_weights = 2*np.random.random((3, 4)) - 1 #size of matrix
secondLayer_weights = 2*np.random.random((4, 1)) - 1
for value in xrange(60000): # loops through training
#pass input through weights to output: three layers
layer0 = input_data
#layer1 takes dot product of the input and weight matrices, then maps them to sigmoid function
layer1 = nonlin(np.dot(layer0, firstLayer_weights))
#layer2 takes dot product of layer1 result and weight matrices, then maps the to sigmoid function
layer2 = nonlin(np.dot(layer1, secondLayer_weights))
#check computer predicted result against actual data
layer2_error = output_data - layer2
#if value is a factor of 10,000, so six times (out of 60,000),
#print how far off the predicted value was from the data
if value % 10000 == 0:
print "Error:" + str(np.mean(np.abs(layer2_error))) #average error
#find out how much to re-adjust weights based on how far off and how confident the estimate
layer2_change = layer2_error * nonlin(layer2, deriv = True)
#find out how layer1 led to error in layer 2, to attack root of problem
layer1_error = layer2_change.dot(secondLayer_weights.T)
#^^sends error on layer2 backwards across weights(dividing) to find original error: BACKPROPAGATION
#same thing as layer2 change, change based on accuracy and confidence
layer1_change = layer1_error * nonlin(layer1, deriv=True)
#modify weights based on multiplication of error between two layers
secondLayer_weights = secondLayer_weights + layer1.T.dot(layer2_change)
firstLayer_weights = firstLayer_weights + layer0.T.dot(layer1_change)如您所见,本节是所涉及的数据:
input_data = np.array([[1, 1, 1],
[0, 0, 0],
[-1, -1, -1],
[-1, 1, -1]])
#also for training
output_data = np.array([[1],
[0],
[-1],
[1]])重量在这里:
firstLayer_weights = 2*np.random.random((3, 4)) - 1 #size of matrix
secondLayer_weights = 2*np.random.random((4, 1)) - 1似乎是在第一代之后,在剩下的编译过程中,权重以最小的效率进行修正,使我相信它们已经达到了一个相对的极小值,如下所示:
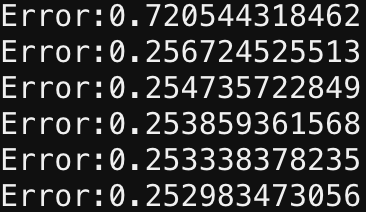
,什么是纠正这个问题的快速有效的替代方案?
回答 2
Stack Overflow用户
回答已采纳
发布于 2016-01-03 21:32:23
网络的一个问题是输出(layer2元素的值)只能在0到1之间变化,因为您使用的是乙状结肠非线性。由于您的四个目标值之一为-1,且最接近的可能预测为0,因此始终至少有25%的错误。以下是一些建议:
- 对输出使用一个热编码:即有三个输出节点--每个
ROCK、PAPER和SCISSORS-and每个节点一个,训练网络计算这些输出的概率分布(通常使用softmax和交叉熵损失)。 - 将网络的输出层设置为线性层(应用权重和偏差,而不是非线性)。要么添加另一个层,要么从当前输出层中消除非线性。
其他您可以尝试的东西,但是不太可能可靠地工作,因为实际上您处理的是分类数据,而不是连续的输出:
- 缩放您的数据,以便培训数据中的所有输出都在0到1之间。
- 使用在-1和1之间产生值的非线性(如tanh)。
Stack Overflow用户
发布于 2016-01-03 19:36:37
每次迭代后,在权重中添加一点噪声。这将使您的程序脱离当地的最小值,并改进(如果可能)。这方面有相当多的文献。例如,在书籍/200705/20070513.pdf。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/34580680
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号