
来自R包的lme4请求缩放变量,即使变量已经缩放
我有一个数据集,有27个变量和30,000个观测值。前17个变量是连续变量,其余变量是二进制变量。当使用指定为所有固定效果+随机效果拦截的模型运行glmer时,我一直收到一条警告消息:
In checkConv(attr(opt, "derivs"), opt$par, ctrl=control$checkConv, :
Model is nearly unidentifiable: very large eigenvalue
- Rescale variables?所有连续变量都使用“尺度”函数进行缩放,中心和标度设置为TRUE。所以我不明白为什么我一直收到这个消息。其中一些变量有一点偏差,这会导致警告吗?
回答 1
Stack Overflow用户
发布于 2015-12-31 23:11:27
tl;博士如果有疑问,可以尝试使用不同的优化器,并确保结果是稳定的,但我可能愿意忽略这个警告,特别是因为您的数据集很大(>10,000枚)。
lme4报告说,参数估计估计的Hessian (二阶导数矩阵)的一些特征值很大(>500);这意味着可能存在数值不稳定性,有时可以通过缩放和调整参数来解决(如果还没有解决)。
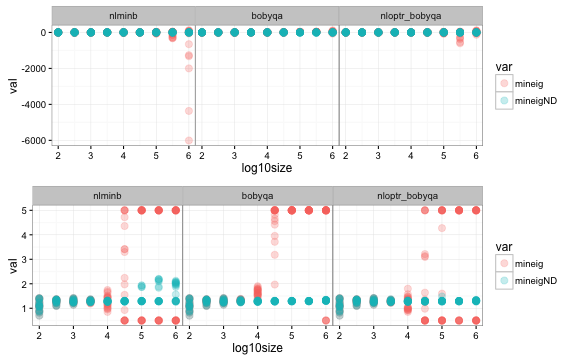
然而,我猜想这是由于对Hessian的错误估计,这导致了对特征值的误导性估计。这是lme4的一个肮脏的秘密--自从我们在几个版本前引入了收敛测试之后,我们就一直在努力使它们正确(这是很难的)。特别是,我们使用了Hessian的朴素有限差分近似,它对大型(>10,000次)数据集的工作效果很差.下面是一个模拟研究的例子(全这里的结果)-蓝色点是通过Richardson外推(numDeriv::hessian)估计的Hessian的最小特征值,粉色点是使用我们的朴素有限差分规则估计的最小特征值。面板有不同的优化器;顶部行不受约束,底部行夹紧到范围(0.5,5) .
https://stackoverflow.com/questions/34550758
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号