
预训练如何改进神经网络的分类?
到目前为止,我读到的许多论文都提到过“预训练网络可以提高反传播错误的计算效率”,并且可以使用RBM或自动编码器来实现。
- 如果我正确理解了,AutoEncoders是通过学习恒等函数来工作的,如果它的隐藏单位小于输入数据的大小,那么它也会进行压缩,但这与提高向后传播误差信号的计算效率有什么关系呢?是因为预先训练过的隐藏单位的权重与其初始值并没有太大的差异吗?
- 假设正在阅读的数据科学家已经知道AutoEncoders将输入作为目标值,因为他们正在学习身份函数,这被认为是无监督学习,但这种方法能应用于第一个隐藏层为特征映射的卷积神经网络吗?每个特征映射都是通过将学习到的内核与图像中的接收字段相转换来创建的。这个博学的内核,如何通过预训练(无监督的方式)来获得?
回答 2
Stack Overflow用户
发布于 2015-12-29 17:44:15
值得注意的是,自动编码器试图学习非平凡的标识函数,而不是标识函数本身。否则它们就根本没用了。训练前的帮助将权重向量移向误差面上的一个良好的起点。然后利用backpropagation算法对这些权值进行改进,基本上是梯度下降。注意,梯度下降被卡在关闭的局部极小值中。
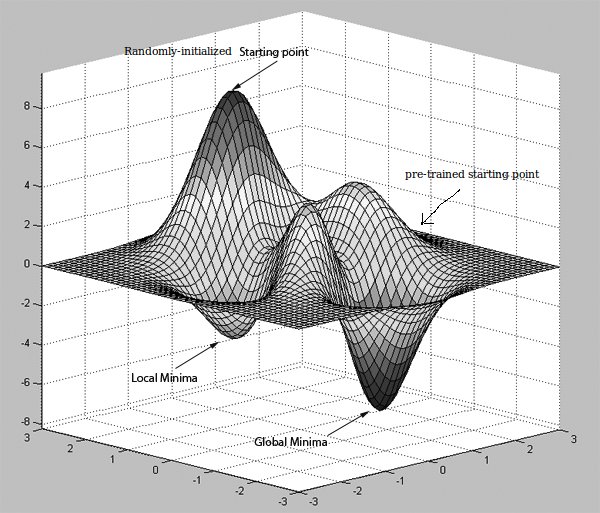
忽略图片中的Global Minima一词,并将其视为另一个更好的局部极小值
直观地说,假设您正在寻找一条从原点A到目的地B的最佳路径。有一张没有显示路线的地图(你在神经网络模型的最后一层得到的错误)可以告诉你该去哪里。但是你可能会把自己放在一条有很多障碍的路线上,上山下山。然后假设有人告诉你一条路线,一条他以前经历过的方向(训练前),然后给你一个新的地图( pre=training阶段的起点)。
这可能是一个直观的原因,为什么从随机权重开始,并立即开始优化模型的反向传播可能不一定会帮助你取得你所获得的性能与预先训练的模型。但是,要注意的是,许多获得最先进结果的模型并不一定要使用预训练,它们可以与其他优化方法(例如adagrad、RMSProp、动量和.)结合使用反向传播。希望避免陷入坏局部极小值。
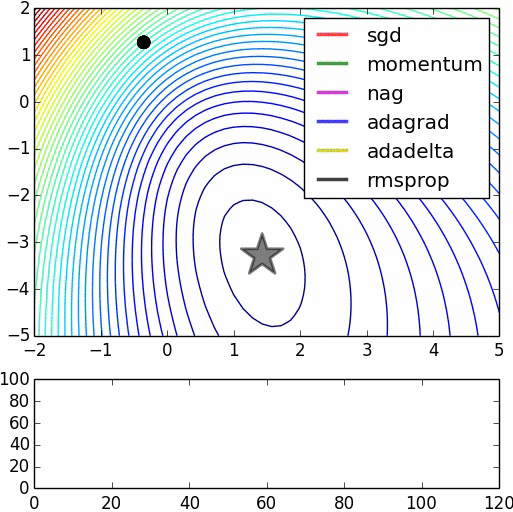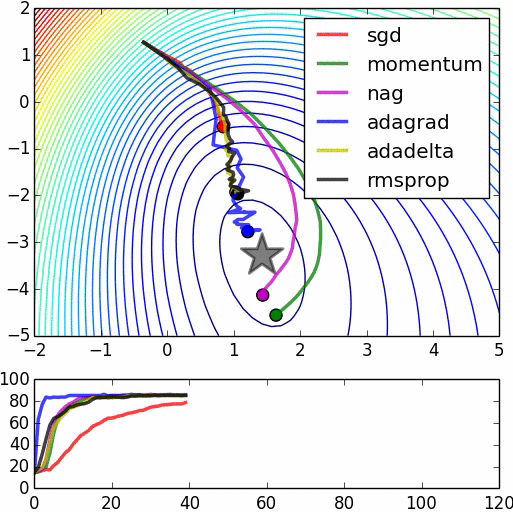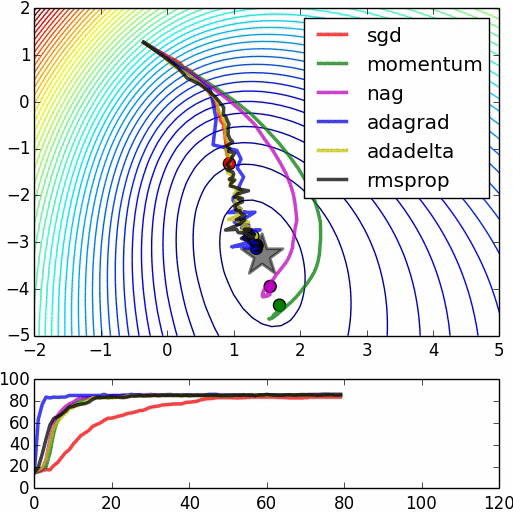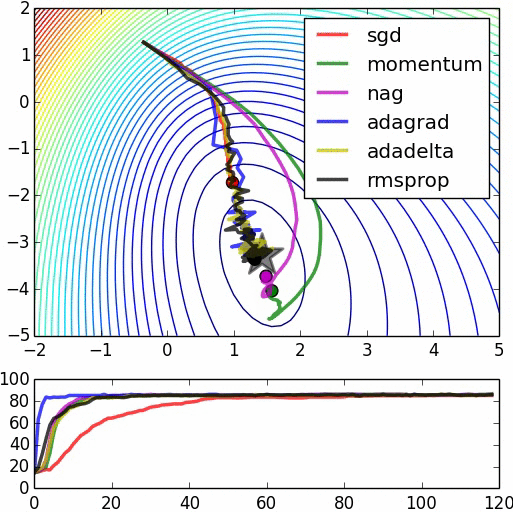
这里是第二张图片的来源。
Stack Overflow用户
发布于 2015-12-29 17:34:27
我对自动编码理论不太了解,但是我做了一些关于RBM的工作。RBMs所做的是预测看到特定类型数据的概率,以便将权重初始化到正确的球场--它被认为是一个(无监督的)概率模型,因此使用已知的标签是不正确的。基本上,这里的想法是,学习速度太大永远不会导致趋同,但太小的学习要花很长时间才能训练。因此,通过“预训练”,找出球体的权重,然后将学习率设置为小,从而使其降到最优值。
至于第二个问题,不,你通常不预先学习内核,至少不是在没有监督的情况下。我怀疑这里的预培训的含义与你的第一个问题有一点不同--这就是说,正在发生的事情是,他们正在采取一个经过预先训练的模型(比如来自模范动物园),并用一套新的数据对其进行微调。
您使用的模型通常取决于您拥有的数据类型和手头的任务。我发现Convnet训练速度更快、效率更高,但并非所有的数据都有转授的意义,在这种情况下,dbns可能是可行的。除非你有少量的数据,否则我会完全使用神经网络以外的东西。
不管怎样,我希望这能帮你澄清一些问题。
https://stackoverflow.com/questions/34514687
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号