
Cuda L2传输开销
我有一个用atomicMin测试渲染点的内核。测试设置在概念用例内存布局中有大量的点。两个缓冲器,一个uint32,用于256 x uint32集群。
namespace Point
{
struct PackedBitfield
{
glm::uint32_t x : 6;
glm::uint32_t y : 6;
glm::uint32_t z : 6;
glm::uint32_t nx : 4;
glm::uint32_t ny : 4;
glm::uint32_t nz : 4;
glm::uint32_t unused : 2;
};
union __align__(4) Packed
{
glm::uint32_t bits;
PackedBitfield field;
};
struct ClusterPositionBitfield
{
glm::uint32_t x : 10;
glm::uint32_t y : 10;
glm::uint32_t z : 10;
glm::uint32_t w : 2;
};
union ClusterPosition
{
glm::uint32_t bits;
ClusterPositionBitfield field;
};
}
//
// launch with blockSize=(256, 1, 1) and grid=(numberOfClusters, 1, 1)
//
extern "C" __global__ void pointsRenderKernel(mat4 u_mvp,
ivec2 u_resolution,
uint64_t* rasterBuffer,
Point::Packed* points,
Point::ClusterPosition* clusterPosition)
{
// extract and compute world position
const Point::ClusterPosition cPosition(clusterPosition[blockIdx.x]);
const Point::Packed point(points[blockIdx.x*256 + threadIdx.x]);
...use points and write to buffer...
}由此产生的SASS如下所示:
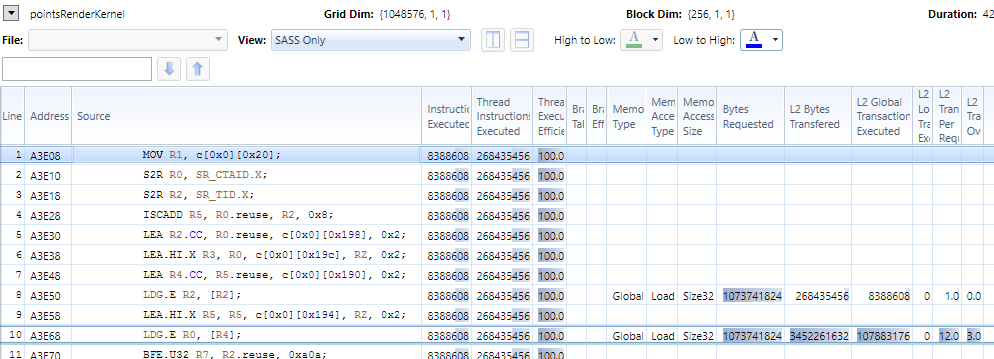
查看内存分析器输出:来自Point::Packed*缓冲区读取的Point::Packed*传输开销是3.0。为什么会这样?内存应该是完全对齐和顺序的。此外,为什么这会自动生成LDG(compute_50,sm_50)?我不需要这个缓存。
回答 1
Stack Overflow用户
发布于 2017-06-12 04:21:56
在用于L2传输开销的工具提示中,它表示它测量“L1和L2之间为L1中的每个请求字节实际传输的字节数”,并且它还表示“越低越好”。
在我的例子中,L2读取Point::Packed的传输开销是1.0。

测试代码
namespace Point
{
struct PackedBitfield
{
uint32_t x : 6;
uint32_t y : 6;
uint32_t z : 6;
uint32_t nx : 4;
uint32_t ny : 4;
uint32_t nz : 4;
uint32_t unused : 2;
};
union __align__(4) Packed
{
uint32_t bits;
PackedBitfield field;
};
struct ClusterPositionBitfield
{
uint32_t x : 10;
uint32_t y : 10;
uint32_t z : 10;
uint32_t w : 2;
};
union ClusterPosition
{
uint32_t bits;
ClusterPositionBitfield field;
};
}
__global__ void pointsRenderKernel(Point::Packed* points, Point::ClusterPosition* clusterPosition)
{
int t_id = blockIdx.x * blockDim.x + threadIdx.x;
clusterPosition[blockIdx.x + blockDim.x] = clusterPosition[blockIdx.x];
points[t_id + blockDim.x * gridDim.x] = points[t_id];
}
void main()
{
int blockSize = 256;
int numberOfClusters = 256;
std::cout << sizeof(Point::Packed) << std::endl;
std::cout << sizeof(Point::ClusterPosition) << std::endl;
Point::Packed *d_points;
cudaMalloc(&d_points, sizeof(Point::Packed) * numberOfClusters * blockSize * 2);
Point::ClusterPosition *d_clusterPositions;
cudaMalloc(&d_points, sizeof(Point::ClusterPosition) * numberOfClusters * 2);
pointsRenderKernel<<<numberOfClusters, blockSize>>>(d_points, d_clusterPositions);
}更新
在我使用最新的司机之前,我在Nsight上遇到了其他一些问题。我将驱动程序降级为默认的CUDA 8.0.61安装程序(从这里下载)附带的版本,并修复了这个问题。安装程序附带的版本是376.51。在Windows 10 64位和Visual 2015上进行了测试,Nsight版本为5.2,我的显卡为cc6.1。
这是我的完整编译器命令:
nvcc.exe -gencode=arch=compute_61,code=\"sm_61,compute_61\“-使用-本地-env-cl-2015年版-Xcompiler "/wd 4819”-ccbin "C:\Program (x86)\Microsoft 14.0\VC\bin\x86_amd64“-I"C:\Program \NVIDIA计算工具包\CUDA\v8.0\包括”-lineinfo -保持-dir x 64 \Release-maxrregcount=0-机器64--编译-cudart静态-DWIN32 -DWIN64 -DNDEBUG -D_CONSOLE -D_MBCS -Xcompiler "/EHsc /W3 /nologo /O2 /FS /Zi /MD“-o x64\Release\kernel.cu.obj kernel.cu”
更新2
当我使用sm_50,compute_50选项编译时,我得到了相同的结果:1.0用于L2传输开销。
https://stackoverflow.com/questions/34455643
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号