
分布式分析中的微服务有界上下文
在我们当前的系统中,我们正在将过去是一个单一应用程序的几个服务切片成一个独立的服务。
我们在分析方面有一个相当标准的架构(类似于lambda):
- 分析HTTP请求并将其推送到流中的前端服务。
- 一种为每种事件构建卷起并直接调用数据库的使用者服务(主要是出于性能原因)。
- 一个报表服务,它读取每个汇总表并返回有意义的数据。
- 一种数据管理服务,每N小时运行一次批处理作业,读取数据并对其进行采样,删除无用的行和短暂的数据/报告等。
该体系结构类似于以下图表:
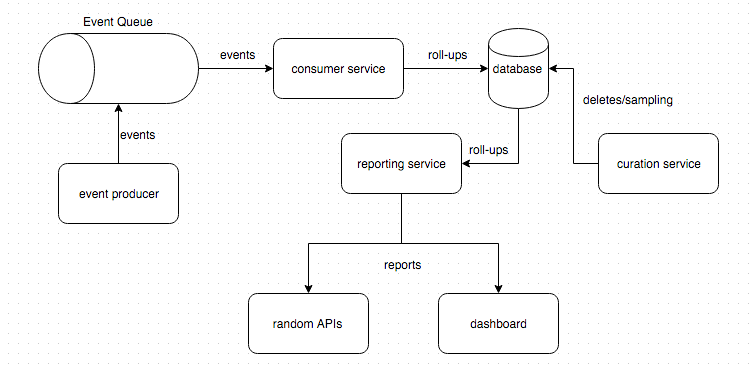
由于使用者和报告服务使用的表是相同的,所以我们破坏了有限的上下文,我们在这里遵循反模式,因为每次我们需要进行模式更改时,我们都需要“同时”部署使用者(创建数据的服务)和报告(读取数据的服务)。然后我们可能也要部署策展人服务。
我能够想出的唯一方法来遵循有限的上下文规则,就是在reporting上公开一个方法,以基于使用者调用参数构建滚动。对于管理服务也是如此,在报告服务中公开管理方法。将这种“报告服务”转化为某种神的服务。
这种解决方案的巨大缺点是无法预测报告的延迟,因为相同的框可能正在执行批处理工作,创建大量的汇总和计算报告,因为服务将具有多重责任。
是否有一种方法可以架构这三种服务(消费者、报告、管理)松散耦合,而不直接依赖于它们之间的数据库集成?
回答 1
Stack Overflow用户
发布于 2015-12-26 09:56:15
是否有一种方法可以架构这三种服务(消费者、报告、管理)松散耦合,而不直接依赖于它们之间的数据库集成?
不要向使用者、报告和管理服务公开数据库,而是公开一个新服务的API (例如REST ),它将专门访问数据库。使这些服务不依赖于数据库,而是依赖于这个API,并向使用者、报告和管理服务隐藏数据库。
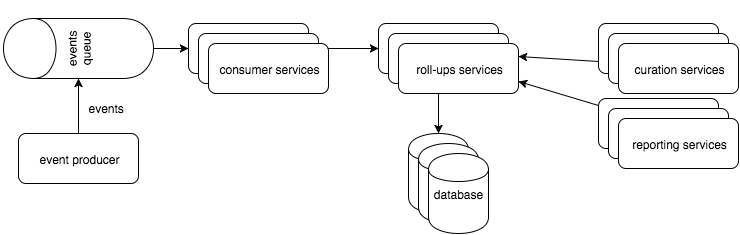
如果您有许多有界上下文,那么您可以为每个有界上下文创建一个单独的服务:
https://stackoverflow.com/questions/34450732
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号