
在R的一系列比赛中,我应该如何计算每支球队的胜利?
在R的一系列比赛中,我应该如何计算每支球队的胜利?
提问于 2015-12-09 00:24:04
我正在寻求关于如何思考和处理这个问题的建议。
我有一个像这样的数据框架,多对球队在多轮比赛中每轮进行多场比赛。我想知道整个赛季每支球队的胜利、输球和平局的数量。
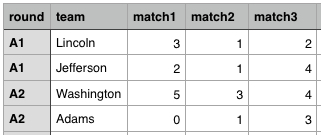
我想过两种方法,但这两种方法似乎都不正确:
- 我可以通过比较两个给定的分数来确定其中之一的胜负/平局,使用if-然后- one函数。但有时一场比赛的其他分数是下面的,有时是上面的。因此,循环使用
apply函数似乎是不对的。 - 或者,我可以使用
dplyr函数按轮分组,并在循环中进行比较。但又有什么功能呢?我不想使用像dplyr这样的总结函数,因为我想生成一个列,它告诉我几个单元格中的每个单元是否都是成功的。
有什么建议吗?谢谢!
回答 3
Stack Overflow用户
回答已采纳
发布于 2015-12-09 00:51:31
这是我的尝试。最初,我使用melt()以长格式输出数据。然后,我在group_by()中创建了一个组变量。然后,我用value改变了每对的顺序,这是比赛的分数。在mutate()中,当两个值(两个分数)相等时,我指定了“领带”。否则,我把“赢”和“输”分配给每一对,因为赢家是第一位的。如果您想要一个宽的格式,您可以使用dcast()。
mydf <- data.frame(round = c("A1", "A1", "A2", "A2"),
team = c("Lincoln", "Jefferson", "Washington", "Adams"),
match1 = c(3, 2, 5, 0),
match2 = c(1, 1, 3, 1),
match3 = c(2, 4, 4, 3),
stringsAsFactors = FALSE)
melt(mydf, id.vars = c("round", "team"), variable.name = "match") %>%
group_by(round, match) %>%
arrange(desc(value)) %>%
mutate(result = { if(value[1] == value[2]){"ties"}else{
c("win", "lose")}
})
# round team match value result
# 1 A1 Lincoln match1 3 win
# 2 A1 Jefferson match1 2 lose
# 3 A1 Lincoln match2 1 ties
# 4 A1 Jefferson match2 1 ties
# 5 A1 Jefferson match3 4 win
# 6 A1 Lincoln match3 2 lose
# 7 A2 Washington match1 5 win
# 8 A2 Adams match1 0 lose
# 9 A2 Washington match2 3 win
# 10 A2 Adams match2 1 lose
# 11 A2 Washington match3 4 win
# 12 A2 Adams match3 3 loseStack Overflow用户
发布于 2015-12-09 01:27:24
您的格式对于回合而言是长的,而对于匹配则是宽的。我会用排名来确定哪支球队更高,每场比赛使用sapply,每轮使用ave。
sapply(mydf[-1:-2], function(x) ave(x, mydf[1], FUN=rank))
# match1 match2 match3
#[1,] 2 1.5 1
#[2,] 1 1.5 2
#[3,] 2 2.0 2
#[4,] 1 1.0 12是赢,1是输,1.5是平局。您可以使用factor()来标记它们。
Stack Overflow用户
发布于 2015-12-09 01:30:12
这是另一个dplyr/tidyr选项
library(dplyr)
library(tidyr)
mydf %>%
gather(match_number, score,
match1:match3) %>%
group_by(round, match_number) %>%
mutate(percent_goals = score / sum(score),
win = percent_goals > 0.5,
tie = percent_goals == 0.5,
lose = percent_goals < 0.5) %>%
gather(outcome, test,
win, tie, lose) %>%
filter(test) %>%
count(team, outcome) %>%
spread(outcome, n, fill = 0)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/34168670
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号