
哪一种k-合并排序在外部排序中更有效
我正在处理一个问题,在这个问题中,我需要对数据的80GB进行排序。我只有1GB主内存来对数据进行排序。显然,我们将在这里应用外部排序方法。但我的问题是哪种k-合并排序会更有效?
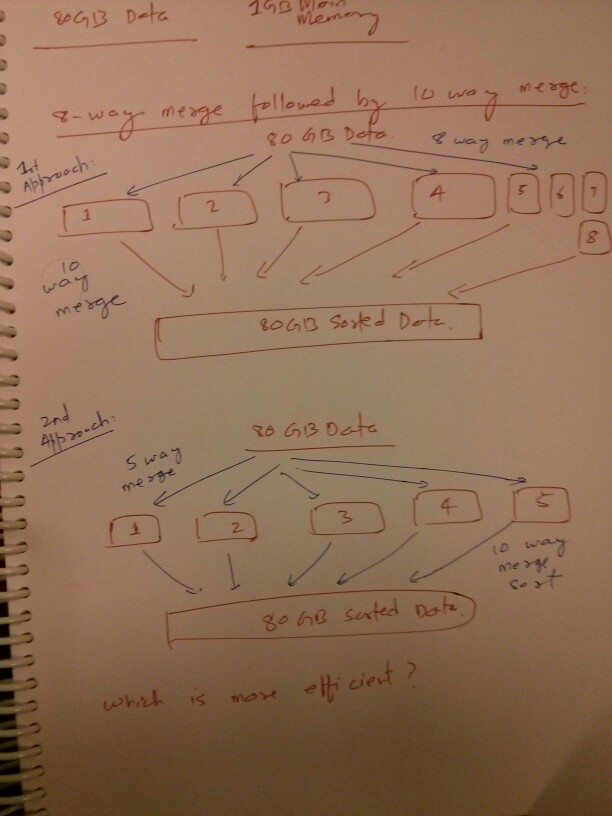
- 8路合并后10路合并
- 5路合并后16路合并
K-合并排序的复杂性是O(nk^2),其中n是元素数.假设我使用此方法计算复杂性:
8路合并,然后是10路合并
8 way merge - O(n*8^2) => O(64n)
10 way merge - O(8n*10^2) => O(800n)
Total time complexity => O(64n) + O(800n)5路合并后16路合并
5 way merge - O(n*5^2) => O(25n)
16 way merge - O(5n*16^2) => O(1280n)
Total time complexity => O(25n) + O(1280n)从时间复杂性来看,5 way merge followed by 16 way merge似乎需要更多的时间。你觉得我的过程对吗?我对此不太自信。
更新:@rcgldr,因为您是说更大的块大小将花费更少的时间来读/写,所以您对这个公式有什么看法:
Time to read/write 1 block = Average Seek time +
Average rotational latency + blocksize/Maximum Transfer Rate根据这个公式,如果块大小很小,那么总的读/写时间也会更短。你觉得这里有什么不对劲吗?或者,我们需要将块的总数与此相乘,以得到所需总时间的精确图像。
回答 1
Stack Overflow用户
发布于 2015-12-07 06:23:28
这是一种外部类型,所以正常的时间复杂度不适用,至少在现实世界中不适用。
为了澄清第一条语句,内存(非外部)中的k路合并(而不是合并排序)合并大小为n的k数组,因此移动k n数据,并且在一个简单的版本中,对每次移动进行k-1比较,因此( in ) (k-1) =n k^2 -n k => O(n k^2)。如果堆/优先级队列/ ..。用于跟踪当前的最小元素集,然后将比较的数量减少到log2(k),因此O(n log2(k))。
内存中n个元素的k路合并排序需要⌈logk(n)⌉⌉ceil(logk(n))通过,每次传递移动n个元素,因此n⌈logk(n)⌉。使用堆/优先级队列/。为了实现k元素的比较,采用了== (log2(K))层(log2(K)),因此(n⌈logk(N)⌉)(⌊logk 2(K)⌋)。如果n是k的幂,k是2的幂,则复杂度为n logk(n) log2(k) =n log2(n)。K与复杂性无关,但实际运行时间可能更好或更糟,k>2意味着比较更多,但移动更少,因此问题是比较开销和运行开销,例如对指向对象的指针数组进行排序。
回到外部排序,假设流程是I/O绑定的,那么复杂性与I/O相关,而不是cpu操作。
这两种方法都需要3次读写80 of的数据。第一遍创建了80个1GB集群的实例。下一次一次合并5或8个集群,最后一次合并16或10个集群。主要问题是一次读取或写入大量数据,以减少随机访问开销。16路合并将把1GB的内存分解成比10路合并更小的块,这可能会使随机访问开销略有不同,因此8/ 10方法可能会更快一些。如果使用固态驱动器进行外部排序,那么随机访问/块大小就不是问题了。
另一个问题是,如果10路或16路合并在内存中运行得足够快,以便合并进程是I/O绑定的。
https://stackoverflow.com/questions/34127438
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号