
简单(工作)手写数字识别:如何改进?
我刚刚写了一个非常简单的手写数字恢复。这是8kb的存档具有以下代码+10个.PNG图像文件。它的作用是:
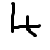
被公认为
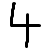
。
简而言之,数据库的每一个数字(50x50像素=250个系数)都是将概括为一个10系数向量(通过保持10个最大奇异值,参见具有奇异值分解的低秩逼近)。
然后,对于要识别的数字,我们将与数据库中的数字的距离最小化。
from scipy import misc
import numpy as np
import matplotlib.pyplot as plt
digits = []
for i in range(11):
M = misc.imread(str(i) + '.png', flatten=True)
U, s, V = np.linalg.svd(M, full_matrices=False)
s[10:] = 0 # keep the 10 biggest singular values only, discard others
S = np.diag(s)
M_reduced = np.dot(U, np.dot(S, V)) # reconstitution of image with 10 biggest singular values
digits.append({'original': M, 'singular': s[:10], 'reduced': M_reduced})
# each 50x50 pixels digit is summarized into a vector of 10 coefficients : the 10 biggest singular values s[:10]
# 0.png to 9.png = all the digits (for machine training)
# 10.png = the digit to be recognized
toberecognizeddigit = digits[10]
digits = digits[:10]
# we find the nearest-neighbour by minimizing the distance between singular values of toberecoginzeddigit and all the digits in database
recognizeddigit = min(digits[:10], key=lambda d: sum((d['singular']-toberecognizeddigit['singular'])**2))
plt.imshow(toberecognizeddigit['reduced'], interpolation='nearest', cmap=plt.cm.Greys_r)
plt.show()
plt.imshow(recognizeddigit['reduced'], interpolation='nearest', cmap=plt.cm.Greys_r)
plt.show()问题:
代码可以工作(您可以在ZIP存档中运行代码),但是我们如何改进它以获得更好的结果呢?(主要是我想象的数学技术)。
例如,在我的测试中,9和3有时会相互混淆。
回答 1
Stack Overflow用户
发布于 2015-12-06 10:59:09
数字识别可能是一个相当困难的领域。特别是当数字是用非常不同或不清楚的方式写的时候。为了解决这一问题,已经采取了许多方法,整个竞争都致力于这一主题。有关示例,请参见Kaggle数字识别器竞赛。这次比赛的基础是著名的MNIST数据集。在那里的论坛上,你会发现很多解决这个问题的想法和方法,但我会给出一些快速的建议。
很多人把这个问题看作是分类问题。解决这些问题的可能算法包括,例如,kNN、神经网络或梯度增强。
然而,一般情况下,仅仅是算法还不足以得到最优的分类率。提高分数的另一个重要方面是特征提取。其思想是计算特征,使区分不同的数字成为可能。此数据集的某些示例功能可能包括彩色像素的数量,或者可能包括数字的宽度和高度。
虽然其他的算法可能不是您想要的,但是添加更多的特性也可以提高您目前正在使用的算法的性能。
https://stackoverflow.com/questions/34116526
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号