
为hts字符参数R创建正确的输入名称
这个问题与hts包无关,但其动机来自于需要在hts包中指定列名中的层次结构(函数hts参数“字符”)。
原始数据:
library(data.table)
Original<-data.table(column_names=c("12_2985_40_4025", "12_2986_26_4027",
"12_3385_17_4863", "48_2570_433_3376"))
Original[,nchar:=nchar(column_names)]
Original原创
names nchar
1: 12_2985_40_4025 15
2: 12_2986_26_4027 15
3: 12_3385_17_4863 15
4: 48_2570_433_3376 16请注意,每行由一个层次结构中的单个时间序列构建的4个粘贴标签组成,例如,Original$names[1]: "12_2985_40_4025是一个类型为"12“、子类型"2985”、子类型"40“和唯一标识符"4025”的时间序列。
说明原始数据层次结构:
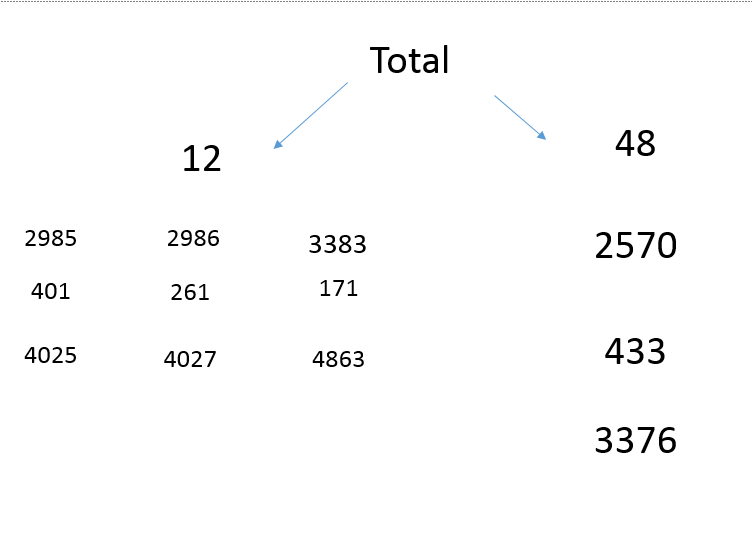
字符参数要求:
整数表示可以读取底层名称的段,以便构造相应的节点结构及其标签。例如,假设下面的一个系列被命名为"VICMelb“,指的是维多利亚州内的墨尔本市。然后将字符指定为c(3,4),表示3个字符(例如“国际中心”)和4个字符(例如"Melb")的状态,所有底部名称必须具有相同的长度,每个片段的字符数与所有系列的字符数相同。
因此,我需要将“原始”格式转换为“必需”格式,以便进一步将其输入到hts对象中,注意到我添加了"l“(可以是任何字符),以便为所有子级别创建相同的长度:
required<-data.table(names=c("12_2985_40l_4025", "12_2986_26l_4027",
"12_3385_17l_4863", "48_2570_433_3376"))
required[,nchar:=nchar(names)]
required必填项
names nchar
1: 12_2985_40l_4025 16
2: 12_2986_26l_4027 16
3: 12_3385_17l_4863 16
4: 48_2570_433_3376 16因此,现在来自hts的以下代码可以工作,因为每个“名称”将被分成4个长度级别:3、5、4、4(包括下划线):
library(hts)
abc <- ts(5 + matrix(sort(rnorm(1000)), ncol = 4, nrow = 100))
colnames(abc) <- required$names
y <- hts(abc, characters=c(3,5,4,4)) #this would work after properly fixing
Alert_forecast <- forecast(y, h=10, method="comb")
plot(Alert_forecast, include=10)我想出的一般解决方案是:(虽然我确实没有把它正确地表述成代码,而不是优雅的),为了将它转换成正确的格式,我想先找到所有4个级别的最大值(对于“名称”的所有值),然后在所有“名称”上运行一个循环,然后在一个循环中分割每个级别,如果它的级别较短,那么它就会粘贴必要的11级,这样它的名称长度就会与其同等级别的所有其他TS一样长。
回答 1
Stack Overflow用户
发布于 2015-12-02 12:28:32
下面是使用stringi包解决这一问题的尝试
library(data.table) #V 1.9.6+
library(stringi)
Original[, tstrsplit(column_names, "_", fixed = TRUE)
][, lapply(.SD, function(x) stri_pad_right(x, max(nchar(x)), "l"))
][, do.call(paste, c(sep = "_", .SD))]
## [1] "12_2985_40l_4025" "12_2986_26l_4027" "12_3385_17l_4863" "48_2570_433_3376"这里的想法是:按_拆分>找到每列的最大长度> pad ls到较短的值>将所有内容与_分隔符组合起来。
https://stackoverflow.com/questions/34042346
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号