
熊猫:多指标计算
熊猫:多指标计算
提问于 2015-10-29 21:39:45
我有一份数据,就像:
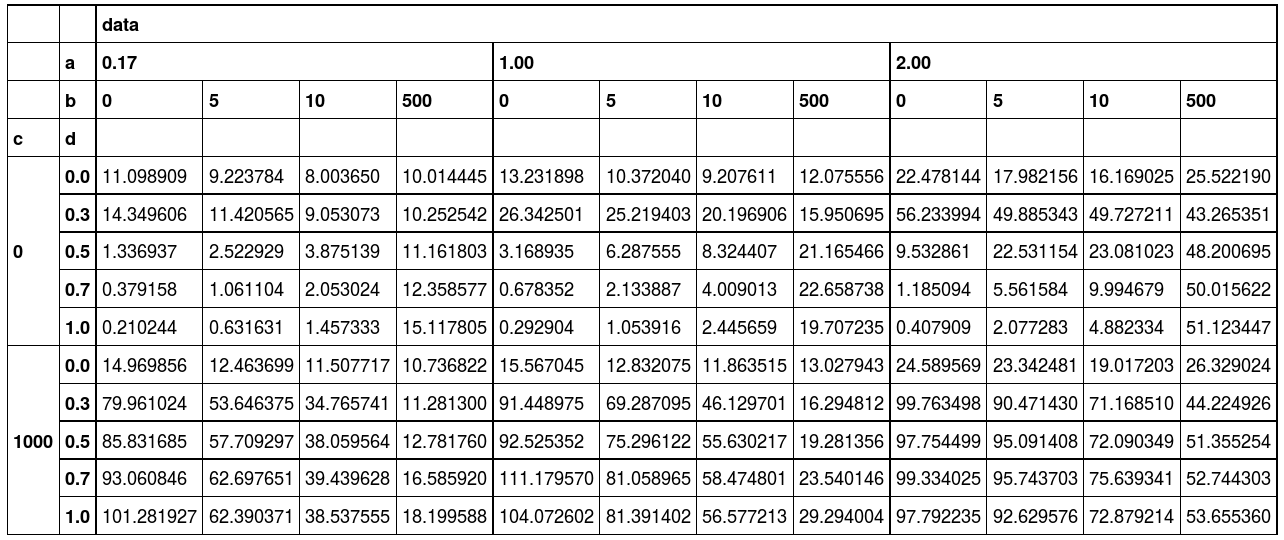
我想减除如下的值:
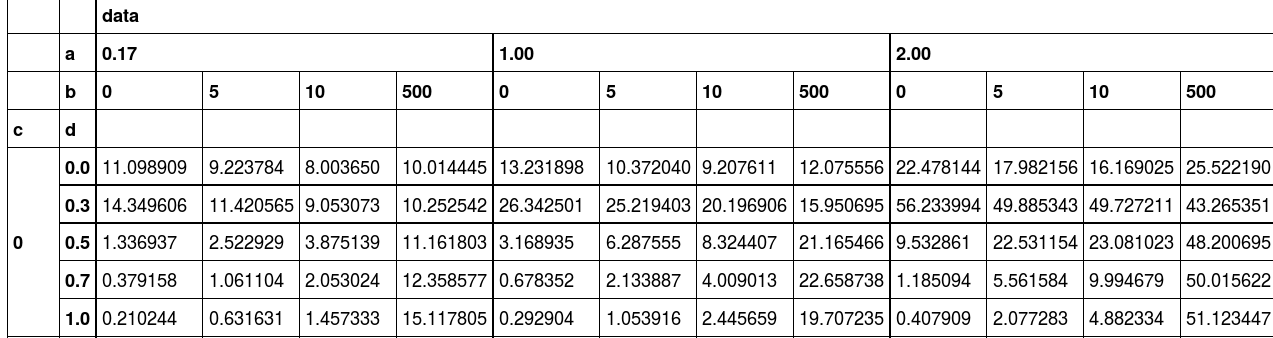
减号
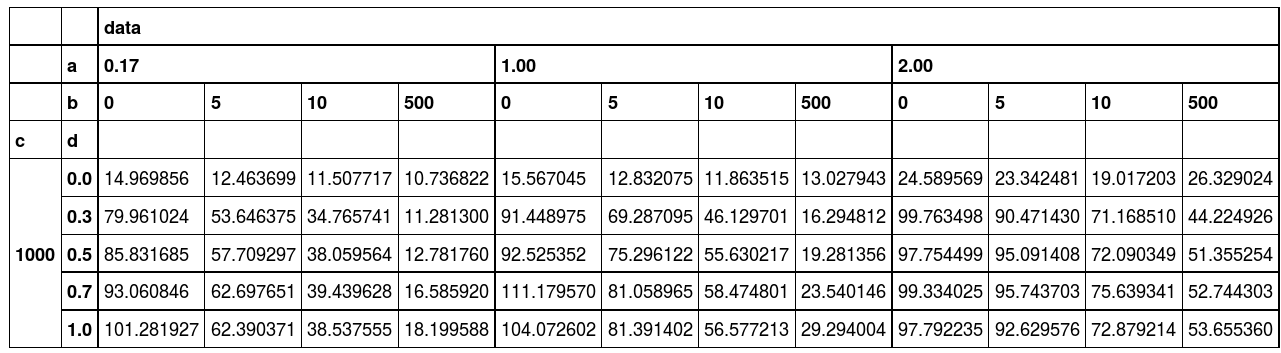
到目前为止,我尝试过的( dataframe:http://pastebin.com/PydRHxcz):
index = pd.MultiIndex.from_tuples([key for key in dfdict], names = ['a','b','c','d'])
dfl = pd.DataFrame([dfdict[key] for key in dfdict],index=index)
dfl.columns = ['data']
dfl.sort(inplace=True)
d = dfl.unstack(['a','b'])我能做到:
d[0:5] - d[0:5]我得到了所有值的零。
但如果我这么做了
d[0:5] - d[5:]我为所有的价值观得到了南方人。我有什么办法做这样的手术吗?
编辑:
起作用的是
dfl.unstack(['a','b'])['data'][5:] - dfl.unstack(['a','b'])['data'][0:5].values但感觉有点笨拙
回答 1
Stack Overflow用户
回答已采纳
发布于 2015-10-29 21:59:38
可以使用loc选择与第一级中的一个标签对应的所有行,如下所示:
In [8]: d.loc[0]
Out[8]:
data ...
a 0.17 1.00
b 0 5 10 500 0 5
d
0.0 11.098909 9.223784 8.003650 10.014445 13.231898 10.372040
0.3 14.349606 11.420565 9.053073 10.252542 26.342501 25.219403
0.5 1.336937 2.522929 3.875139 11.161803 3.168935 6.287555
0.7 0.379158 1.061104 2.053024 12.358577 0.678352 2.133887
1.0 0.210244 0.631631 1.457333 15.117805 0.292904 1.053916所以做减法看起来就像:
In [11]: d.loc[0] - d.loc[1000]
Out[11]:
data ...
a 0.17 1.00
b 0 5 10 500 0 5
d
0.0 -3.870946 -3.239915 -3.504068 -0.722377 -2.335147 -2.460035
0.3 -65.611418 -42.225811 -25.712668 -1.028758 -65.106473 -44.067692
0.5 -84.494748 -55.186368 -34.184425 -1.619957 -89.356417 -69.008567
0.7 -92.681688 -61.636548 -37.386604 -4.227343 -110.501219 -78.925078
1.0 -101.071683 -61.758741 -37.080222 -3.081782 -103.779698 -80.337487页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/33425097
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号