
星火RDD groupByKey + join与join性能
星火RDD groupByKey + join与join性能
提问于 2015-10-24 21:13:29
我正在使用星火在集群上,我正在与其他用户共享。因此,仅仅根据运行时间来判断哪个代码运行效率更高是不可靠的。因为当我运行效率更高的代码时,可能会有人运行巨大的数据,使我的代码执行时间更长。
所以我可以问两个问题:
- 我使用
join函数连接2RDDs,并在使用join之前尝试使用groupByKey(),如下所示: rdd1.groupByKey().join(rdd2) 似乎花了更长的时间,但是我记得当我使用Hadoop时,这个组使我的查询运行得更快。由于Spark使用的是惰性评估,我想知道groupByKey在join之前是否会使事情变得更快 - 我注意到Spark有一个SQL模块,到目前为止我真的没有时间去尝试它,但是我能问一下SQL模块和类似于RDD的SQL函数之间有什么不同吗?
回答 2
Stack Overflow用户
回答已采纳
发布于 2015-10-26 11:06:14
- 没有理由让
groupByKey后面跟着join比join更快。如果rdd1和rdd2没有分区器或分区器的不同,那么一个限制因素就是简单地对HashPartitioning进行洗牌。 通过使用groupByKey,不仅通过保持分组所需的可变缓冲区增加了总成本,而且更重要的是,您使用了额外的转换,这将导致一个更复杂的DAG。groupByKey+join: rdd1 = sc.parallelize(("a",1),("a",3),("b",2)) rdd2 =sc.parallelize(“a”,5),("c",6),("b",7)) rdd1.groupKey().join(Rdd2)
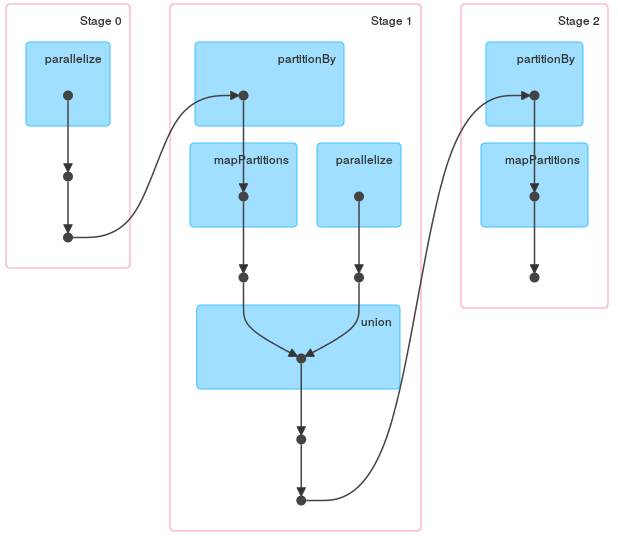
仅与join:
rdd1.join(rdd2)
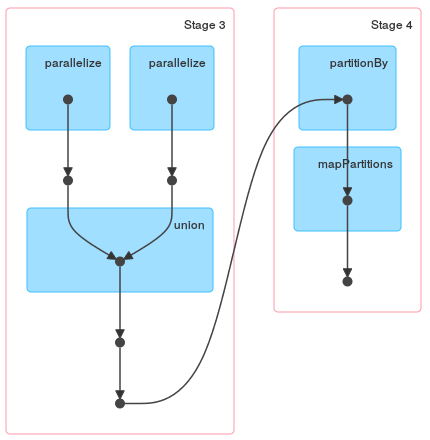
最后,这两个计划甚至不是等价的,为了获得相同的结果,您必须在第一个计划中添加一个额外的flatMap。
- 这是一个相当广泛的问题,但要强调主要的区别:
- `PairwiseRDDs` are homogeneous collections of arbitrary`Tuple2` elements. For default operations you want key to be hashable in a meaningful way otherwise there are no strict requirements regarding the type. In contrast DataFrames exhibit much more dynamic typing but each column can only contain values from a [supported set of defined types](https://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.types.package). It is possible to define [UDT](https://stackoverflow.com/q/32440461/1560062) but it still has to be expressed using basic ones.
- DataFrames use a [Catalyst Optimizer](https://databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html) which generates logical and physical execution planss and can generate highly optimized queries without need for applying manual low level optimizations. RDD based operations simply follow dependency DAG. It means worse performance without custom optimization but much better control over execution and some potential for fine graded tuning.
还有一些要读的东西:
Stack Overflow用户
发布于 2015-10-26 12:54:48
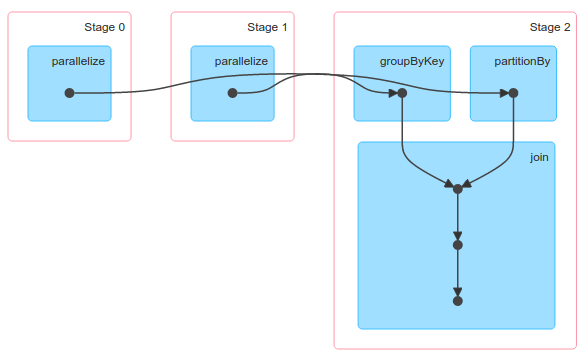
我基本上同意there 323的回答,但我认为有理由期望join在groupByKey之后更快。groupByKey减少了数据量,并按键对数据进行了分区。这两种方法都有助于提高后续join的性能。
我不认为前者(缩小的数据大小)是重要的。为了获得后者(分区)的好处,您需要以相同的方式对其他RDD进行分区。
例如:
val a = sc.parallelize((1 to 10).map(_ -> 100)).groupByKey()
val b = sc.parallelize((1 to 10).map(_ -> 100)).partitionBy(a.partitioner.get)
a.join(b).collect
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/33323422
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号