
反向传播激活导数
正如视频中所解释的,我已经实现了反向传播。https://class.coursera.org/ml-005/lecture/51
这似乎是成功的,通过梯度检查,并允许我在MNIST数字上进行训练。
然而,我注意到了大多数关于反向传播的解释计算输出增量为
D= (a )* f'(z) 算法
而视频用的是。
D= (a - y)
当我将我的增量乘以激活导数(乙状结肠导数)时,我不再得到与梯度检查相同的梯度(至少相差一个数量级)。
是什么让安德鲁·吴(视频)省略了输出增量激活的导数?为什么会起作用呢?然而,当添加导数时,不正确的梯度是计算的吗?
编辑
我现在已经测试了线性和乙状结肠激活函数的输出,梯度检查只有当我使用Ng的δ方程(没有乙状结肠导数)时,才通过这两种情况。
回答 3
Stack Overflow用户
发布于 2015-10-09 04:29:42
找到我的答案了,这里。输出增量确实需要由激活的导数乘法,如in。
D= (a - y) * g'(z)
然而,Ng正在使用交叉熵代价函数,它导致了一个δ,它取消了g'(z),从而得到了视频中所示的d=a计算。如果使用均方误差代价函数,则必须存在激活函数的导数。
Stack Overflow用户
发布于 2015-10-06 07:47:56
当使用神经网络时,它取决于学习任务,如何设计你的网络。回归任务的一种常见方法是对输入层和所有隐藏层使用tanh()激活函数,然后输出层使用线性激活函数(取自这里)。
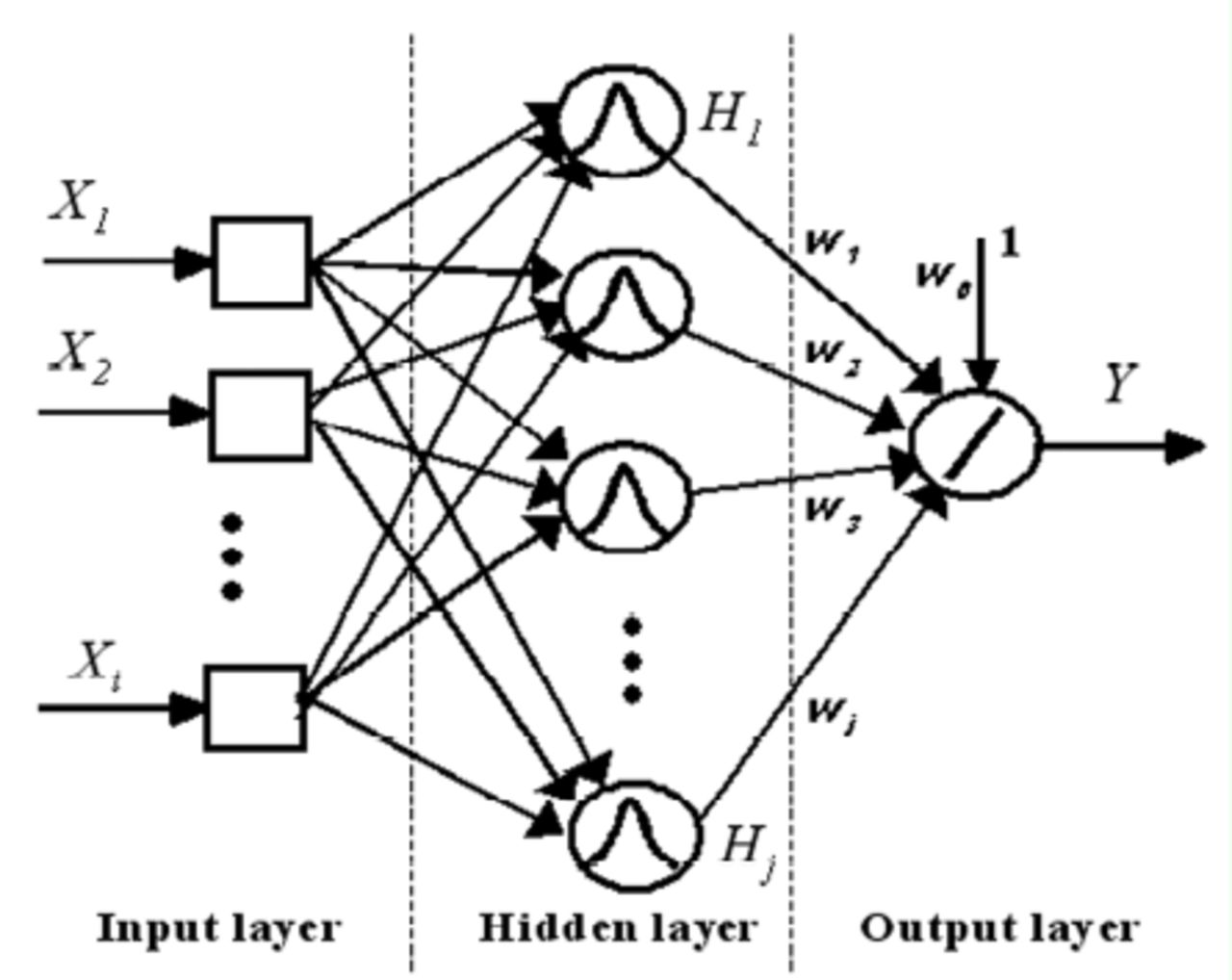
我没有找到源头,但是有一个定理说,使用非线性和线性激活函数可以更好地逼近目标函数。使用不同的激活函数的示例可以找到这里和这里。
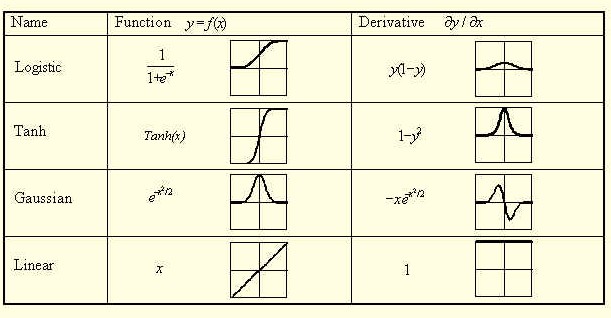
这是许多不同类型的灭活功能,可以使用(img从这里)。如果你看一下这些导数,你会发现linar函数的导数等于1,这就不再被提及了。这也是吴的解释,如果你看看视频中的第12分钟,你就会发现他在谈论输出层。
关于反向传播的-算法
“当神经元位于网络的输出层时,它会得到自己想要的响应。我们可以使用e(n) = d(n) - y(n)计算与该神经元相关的误差信号e(n);见图4.3。在确定了e(n)之后,我们发现计算局部梯度是一件很简单的事情……当神经元位于网络的一个隐层时,该神经元没有指定的期望响应。因此,一个隐藏神经元的错误信号必须递归地确定,并根据与之直接相连的所有神经元的错误信号进行反向工作。”
Haykin,Simon S.,等人.神经网络和学习机器。上萨德尔河:皮尔逊教育,2009年。P 159-164
Stack Overflow用户
发布于 2019-01-17 00:44:05
下面是链接,解释了反向传播背后的所有直觉和数学。
吴家富正在使用交叉熵成本函数,定义如下:
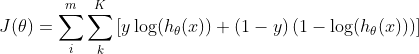
当计算与最后一层中的θ参数有关的偏导数时,我们得到的是:
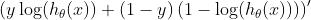
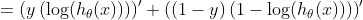
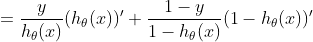
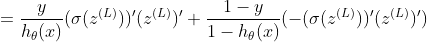
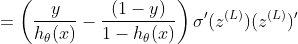
请参阅本文末尾的σ(z)导数,它在以下内容中被替换:
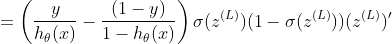
最后一层"L“,
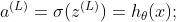
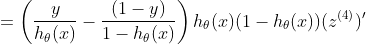
如果我们乘:
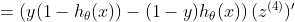
对于σ(z)的偏导数,我们得到的是:
https://stackoverflow.com/questions/32963446
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号