
使用R提取html标记中的内容
使用R提取html标记中的内容
提问于 2015-10-03 10:05:27
我现在正试图提取特定html标记之间的内容,例如:
<dl class="search-advanced-list">
<dt>
<h2><a id="/advanced-search?intercept=adv&as-advanced=+documenttype%3Asource title:%22ADB%22&as-type=advanced" name="ADB">ADB</a></h2>
</dt>
<dd>Allgemeine deutsche Biographie. Under the auspices of the Historical Commission of the Royal Academy of Sciences. 56 vols. Leipzig: Duncker & Humblot. 1875–1912.</dd>
<dt>
<h2><a id="/advanced-search?intercept=adv&as-advanced=+documenttype%3Asource title:%22AMS%22&as-type=advanced" name="AMS">AMS</a></h2>
</dt>
<dd>American men of science. J. McKeen Cattell, ed. Editions 1–4, New York: 1906–27.</dd>
<dt>
<h2><a id="/advanced-search?intercept=adv&as-advanced=+documenttype%3Asource title:%22Abbott%2C+C.+C.+1861%22&as-type=advanced" name="Abbott__C__C__1861">Abbott, C. C. 1861</a></h2>
</dt>
<dd>Abbott, Charles Compton. 1861. Notes on the birds of the Falkland Islands. Ibis 3: 149–67.</dd>
...
</dl>我计划提取<h2> </h2>中的内容以及<dd>和</dd>中的内容。我在stackOverFlow上搜索了类似的问题,但仍然找不出答案,有没有人用R来解决这个问题呢?
回答 3
Stack Overflow用户
回答已采纳
发布于 2015-10-03 11:24:48
这将创建一个两列矩阵m,其第一列为h2,第二列为关联的dd值。由于问题中没有关于输入形式的信息,我们假设输入是字符串Lines,但是如果不是,则可以适当地更改htmlTreeParse行。请尝试?htmlTreeParse获取更多信息。
library(XML)
doc <- htmlTreeParse(Lines, asText = TRUE, useInternalNodes = TRUE)
f <- function(x) cbind(h2 = xmlValue(x), dd = xpathSApply(x, "//dd", xmlValue))
L <- xpathApply(doc, "//h2", f)
m <- do.call(rbind, L)在这里,我们显示h2列和dd列的前10个字符:
> cbind(h2 = m[,1], dd = substr(m[,2], 1, 10))
h2 dd
[1,] "ADB" "Allgemeine"
[2,] "ADB" "American m"
[3,] "ADB" "Abbott, Ch"
[4,] "AMS" "Allgemeine"
[5,] "AMS" "American m"
[6,] "AMS" "Abbott, Ch"
[7,] "Abbott, C. C. 1861" "Allgemeine"
[8,] "Abbott, C. C. 1861" "American m"
[9,] "Abbott, C. C. 1861" "Abbott, Ch"这是上面使用的输入:
Lines <- '<dl class="search-advanced-list">
<dt>
<h2><a id="/advanced-search?intercept=adv&as-advanced=+documenttype%3Asource title:%22ADB%22&as-type=advanced" name="ADB">ADB</a></h2>
</dt>
<dd>Allgemeine deutsche Biographie. Under the auspices of the Historical Commission of the Royal Academy of Sciences. 56 vols. Leipzig: Duncker & Humblot. 1875–1912.</dd>
<dt>
<h2><a id="/advanced-search?intercept=adv&as-advanced=+documenttype%3Asource title:%22AMS%22&as-type=advanced" name="AMS">AMS</a></h2>
</dt>
<dd>American men of science. J. McKeen Cattell, ed. Editions 1–4, New York: 1906–27.</dd>
<dt>
<h2><a id="/advanced-search?intercept=adv&as-advanced=+documenttype%3Asource title:%22Abbott%2C+C.+C.+1861%22&as-type=advanced" name="Abbott__C__C__1861">Abbott, C. C. 1861</a></h2>
</dt>
<dd>Abbott, Charles Compton. 1861. Notes on the birds of the Falkland Islands. Ibis 3: 149–67.</dd>
</dl>'Stack Overflow用户
发布于 2015-10-03 10:52:23
htmlpattern <- "</?\\w+((\\s+\\w+(\\s*=\\s*(?:\".*?\"|'.*?'|[^'\">\\s]+))?)+\\s*|\\s*)/?>"
plain.text <- gsub(htmlpattern, "\\1", txt)
cat(plain.text) 注意: txt是html文本。
Stack Overflow用户
发布于 2015-10-03 10:13:00
您可以使用regex,并可以使用以下搜索字符串匹配数据
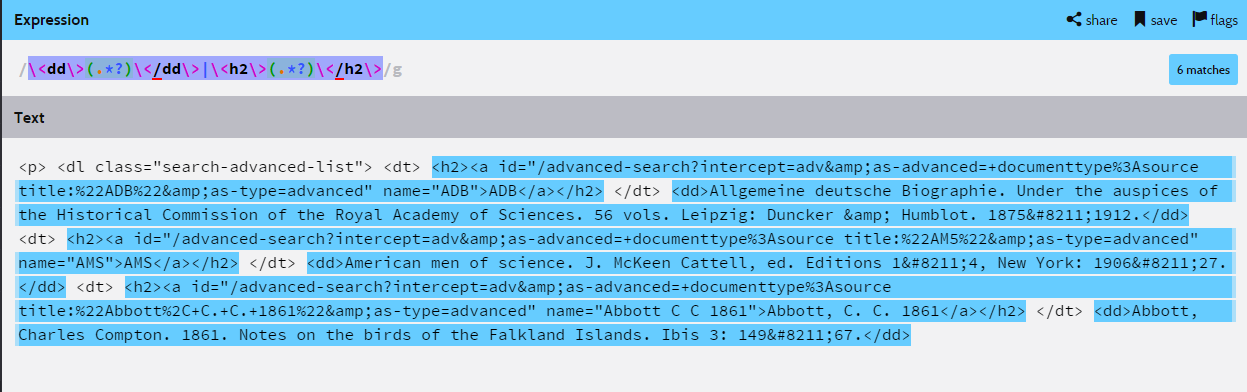
/\<dd\>(.*?)\</dd\>|\<h2\>(.*?)\</h2\>/g
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/32921284
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号